깊은 신경망 학습의 일관성 문제와 해결 방안
초록
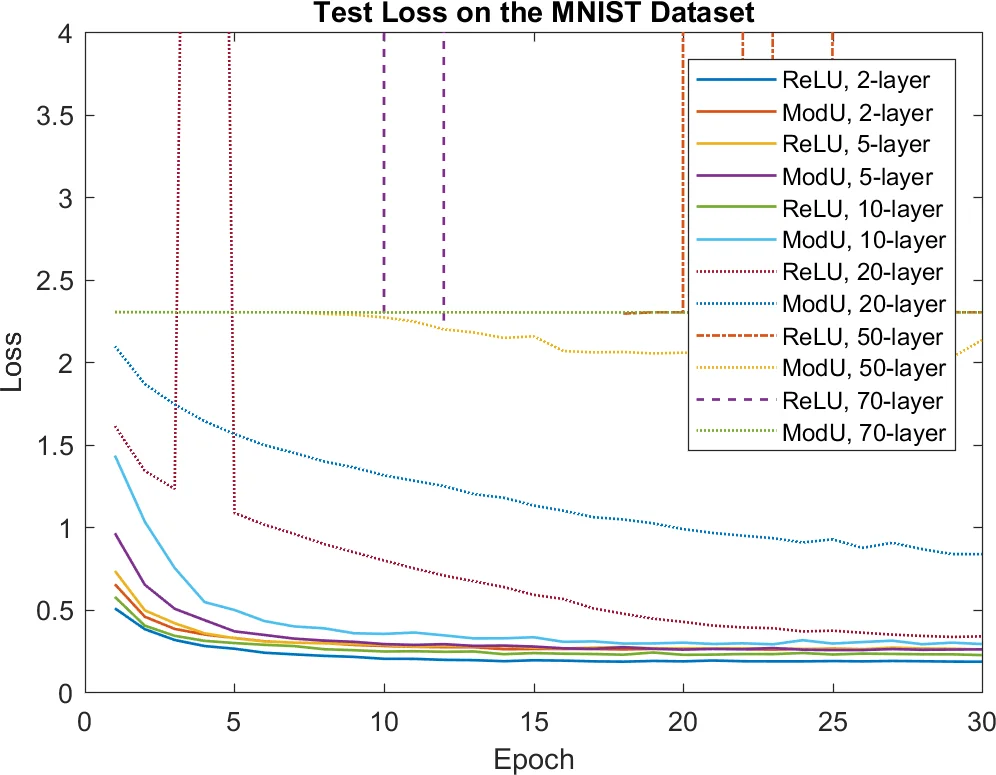
본 논문은 딥 뉴럴 네트워크 학습이 어려운 원인을 세 가지 “일관성” 문제—층별 학습 속도, 입력·잔차 스케일, 잔차 전파—로 규정하고, 각각을 2차 최적화 기법으로 해결하는 방법을 제시한다. 층별 최소화 문제를 선형 근사와 정규화된 뉴턴 단계로 변환하고, RMS 기반 정규화로 스케일 불일치를 해소한다. 마지막으로 연산자 이론을 이용해 소실되는 그래디언트 현상을 선형대수의 기본정리와 연결, 계약성(contraction) 네트워크 설계 원칙을 도출한다. 실험을 통해 제안 기법이 학습 속도와 최종 성능을 모두 개선함을 보인다.
상세 분석
논문은 딥러닝 학습이 오래전부터 “학습 속도 불일치”, “스케일 불일치”, “잔차 전파 불일치”라는 세 가지 근본적인 일관성 문제에 기인한다고 주장한다. 첫 번째 문제는 층마다 최적 학습률이 다름에도 불구하고 전통적인 SGD가 전역 학습률 하나만을 사용한다는 점이다. 저자는 각 층을 독립적인 선형 모델로 근사하고, 잔차 rᵢ와 입력 Xᵢ를 이용해 최소화 문제 minₚ ½‖P Xᵢ + Rᵢ‖²를 정의한다. 정규화된 뉴턴 단계 P = −∂z/∂Wᵢ · ( XᵢXᵢᵀ + λI )⁻¹ 는 실제로 레벤버그‑마르쿠르트 알고리즘의 층별 버전이며, 1차 방법에 비해 커브처 정보를 활용해 학습 속도를 층마다 동일하게 만든다. 구현 측면에서는 XᵢXᵢᵀ의 차원이 수백 수준일 때는 직접 행렬 곱·역을 수행해도 충분히 빠르지만, 수천 차원에서는 stochastic pre‑conditioning을 도입해 작은 청크로 나누어 연산 비용을 크게 낮춘다.
두 번째 문제인 스케일 불일치는 깊은 층으로 갈수록 입력값은 매우 작은 범위(≈10⁻³)로 압축되는 반면, 잔차는 큰 폭(≈10)으로 변동한다는 관찰에서 출발한다. 이는 동일한 λ값을 사용하면 정규화된 뉴턴 단계가 폭발하거나 소멸하게 만든다. 저자는 배치 정규화와 달리, 입력을 RMS(제곱 평균)로 나누는 간단한 정규화를 제안한다. RMS는 미니배치에서 추정하고 이동 평균으로 부드럽게 업데이트되며, 이를 통해 모든 층의 입력 스케일을
댓글 및 학술 토론
Loading comments...
의견 남기기