산업 현장용 토픽 모델링 오픈소스 툴킷 Familia
초록
Familia는 기업 환경에서 토픽 모델링을 손쉽게 적용하도록 설계된 오픈소스 툴킷이다. 문서 표현과 텍스트 매칭이라는 두 가지 핵심 활용 패러다임을 지원하며, LDA, SentenceLDA, TWE 등 사전 학습된 모델을 제공한다. 논문에서는 문서 분류·클러스터링·정보 풍부도 평가, 짧은‑짧은·짧은‑긴·긴‑긴 텍스트 매칭 등 다양한 산업 사례를 통해 모델 선택과 활용 방법을 구체적으로 안내한다.
상세 분석
본 논문은 산업 현장에서 토픽 모델링이 직면한 두 가지 주요 장애물—(1) 기존 모델의 구현이 제한적이며(특히 LDA와 PLSA 외에 공개 구현이 거의 없음), (2) 연구 중심의 모델 개발에 비해 실제 적용 방법에 대한 가이드가 부족함—을 명확히 진단한다. 이를 해결하기 위해 저자들은 ‘Familia’라는 통합 툴킷을 공개하고, 두 가지 실용적 패러다임을 정의한다. 첫 번째는 semantic representation으로, 문서를 토픽 분포 혹은 토픽‑임베딩 형태로 변환해 downstream 머신러닝 모델(GDBT, K‑means 등)의 피처로 활용한다. 구현 측면에서 Gibbs sampling과 Metropolis‑Hastings 두 가지 MCMC 알고리즘을 제공해 정확도와 속도 사이의 트레이드오프를 선택할 수 있게 했다. 두 번째는 semantic matching으로, 짧은‑짧은, 짧은‑긴, 긴‑긴 텍스트 간 유사도 계산을 지원한다. 여기서는 토픽 기반 확률 모델링(예: Eq.3)과 토픽‑워드 임베딩을 결합한 코사인 유사도, Hellinger Distance, Jensen‑Shannon Divergence 등을 활용한다.
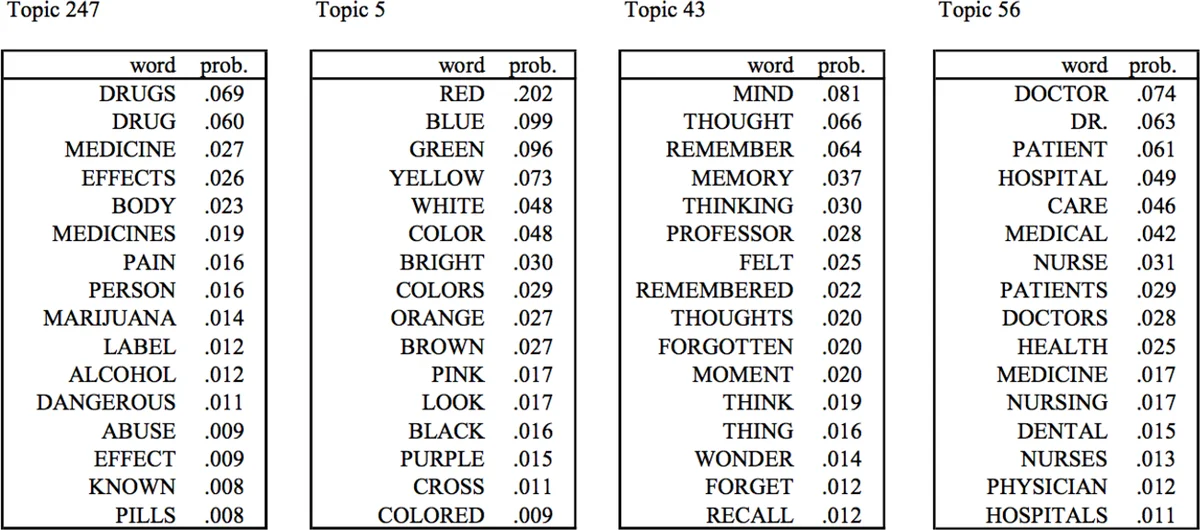
툴킷에 포함된 사전 학습 모델은 각각의 특성을 갖는다. LDA는 전통적인 문서‑토픽 혼합 모델로 대규모 코퍼스에 적합하지만 고빈도 단어에 편향될 수 있다. SentenceLDA는 문장을 최소 단위로 가정해 보다 미세한 토픽 할당이 가능해 광고 페이지와 같은 짧은 문장 집합에 유리하다. TWE는 LDA 토픽을 보조 정보로 사용해 워드 임베딩을 학습함으로써 저빈도 단어의 의미를 보강한다. 이러한 모델들을 실제 산업 데이터(수십억 문서 규모)에서 사전 학습시켜 제공함으로써, 엔지니어는 데이터 전처리와 모델 학습에 드는 비용을 크게 절감한다.
논문은 네 가지 주요 응용 시나리오를 제시한다. (1) 문서 분류: 뉴스 기사에 LDA 토픽 분포를 피처로 추가해 GBDT 성능을 크게 향상시켰다. (2) 문서 클러스터링: 토픽 분포 기반 K‑means 클러스터링으로 주제별 군집을 직관적으로 도출했다. (3) 문서 정보 풍부도: 토픽 분포 엔트로피를 활용해 문서의 내용 다양성을 정량화하고, 검색 랭킹에 반영했다. (4) 텍스트 매칭: 짧은‑짧은 매칭에서는 TWE 임베딩과 코사인 유사도를, 짧은‑긴 매칭에서는 SentenceLDA 토픽 분포를 이용한 확률적 매칭을, 긴‑긴 매칭에서는 토픽 분포 간 HD·JSD 거리를 활용해 광고·추천·키워드 추출 등 다양한 서비스에 적용했다. 특히, 사용자 프로파일을 가상의 문서로 구성하고 토픽 분포 간 거리를 기반으로 개인화 뉴스·소설 추천을 구현한 사례는 실제 서비스에서 클릭률·정밀도 향상을 입증했다.
기술적 강점으로는 (1) 다양한 MCMC 옵션 제공으로 정확도·속도 선택 가능, (2) 통합 API를 통한 토픽 질의(최근접 단어, 토픽‑워드)와 매칭 함수 제공, (3) 대규모 사전 학습 모델 배포로 초기 구축 비용 최소화, (4) 실제 산업 사례를 통한 가이드라인 제공으로 엔지니어가 모델 선택·튜닝에 소요되는 시간을 크게 단축한다는 점이다. 다만, 논문에서는 모델 파라미터 튜닝 가이드가 다소 부족하고, 최신 딥러닝 기반 토픽 모델(예: Neural Topic Model)과의 비교가 없다는 한계가 있다. 향후 버전에서는 이러한 최신 모델을 플러그인 형태로 확장하고, 자동 파라미터 최적화 도구를 제공한다면 더욱 포괄적인 산업용 토픽 툴킷이 될 것이다.
댓글 및 학술 토론
Loading comments...
의견 남기기