GPU 실행 패턴 마이닝으로 딥러닝 성능 분석하는 DeepProf
초록
DeepProf는 TensorFlow 기반 딥러닝 프로그램의 GPU 트레이스를 자동으로 전처리하고, suffix tree를 이용해 반복되는 실행 패턴을 추출한다. 추출된 패턴을 그래프로 시각화해 병목 현상을 진단하고, TensorFlow의 GPU 사용 특성을 정량적으로 제시한다.
상세 분석
본 논문은 딥러닝 프레임워크가 제공하는 고수준 API와 실제 GPU에서 수행되는 저수준 연산 사이의 격차를 해소하기 위해 두 가지 핵심 기술을 제안한다. 첫 번째는 GPU 트레이스의 규모가 수십 메가바이트에 달해 인간이 직접 분석하기 어려운 점을 고려해, suffix tree 자료구조를 활용해 O(n) 공간에서 모든 연산을 정렬·분할하는 방법이다. suffix tree는 문자열의 모든 접미사를 효율적으로 저장하므로, 연산 시퀀스(예: kernel 호출, memcpy)에서 반복되는 서브시퀀스를 빠르게 탐지할 수 있다. 이를 통해 딥러닝 애플리케이션이 반복적으로 수행하는 ‘iteration’ 수준의 실행 흐름을 자동으로 식별한다. 두 번째는 식별된 반복 패턴을 기반으로 성능 지표(예: kernel 실행 시간, 메모리 전송량, 스트림 병렬도)를 그래프로 시각화하는 단계이다. 이 그래프는 각 스트림별 연산 순서를 명확히 보여주어, 개발자가 CPU‑GPU 비동기 호출, 스트림 간 경쟁, 불필요한 그래프 성장 등을 한눈에 파악하도록 돕는다.
논문은 TensorFlow의 데이터플로우 그래프가 내부적으로 어떻게 CUDA 커널과 메모리 복사 연산으로 변환되는지를 상세히 분석한다. 특히, TensorFlow 세션이 매 반복마다 그래프에 새로운 노드를 추가하는 ‘graph growth’ 현상이 발생하면, 매번 전체 그래프 초기화가 수행되어 심각한 성능 저하를 초래한다는 사례를 제시한다. 기존 프로파일러(NVProf, TensorFlow timeline)는 각각 CUDA 레벨 혹은 세션‑레벨 정보를 제공하지만, 두 도구 모두 연산 흐름과 소스 코드 간의 매핑이 부족하고, 대용량 트레이스를 수동으로 탐색해야 하는 한계가 있다. DeepProf는 이러한 문제를 해결하기 위해, 트레이스에서 동일 스트림을 기준으로 연산을 정렬하고, suffix tree 기반 패턴 매칭으로 반복 구간을 자동 추출한다.
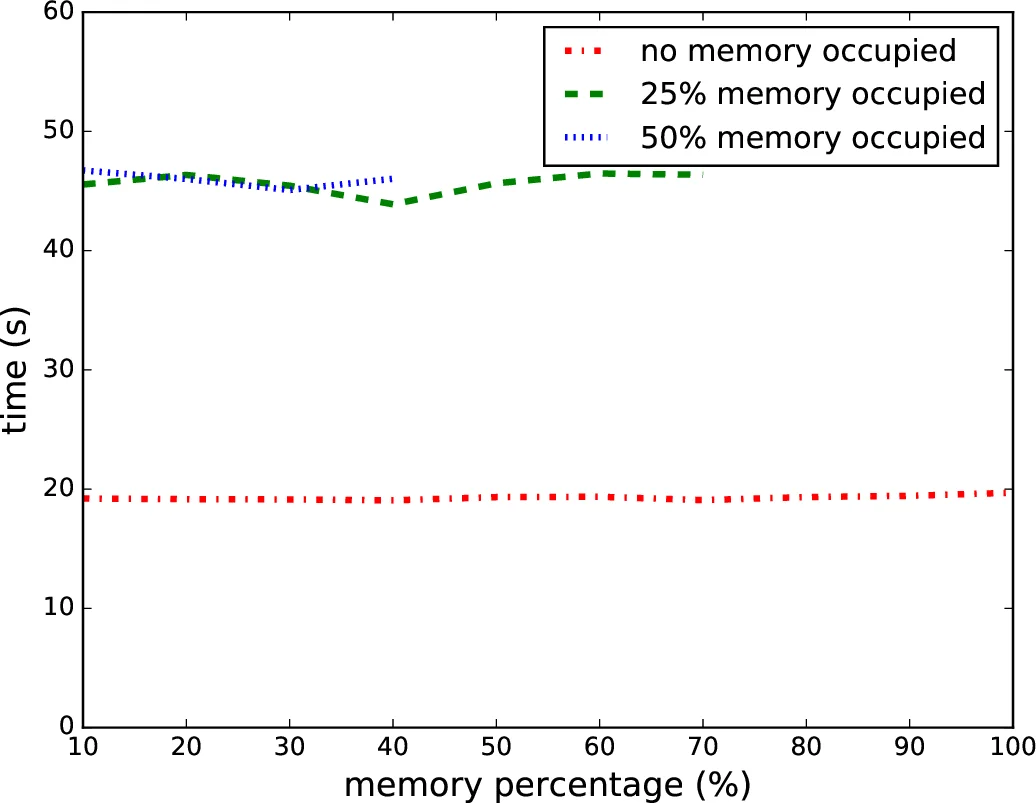
실험에서는 여러 TensorFlow 모델(CNN, RNN, GAN)과 다양한 GPU(NVIDIA GTX 1080Ti, RTX 2080)에서 DeepProf를 적용했으며, 그래프 성장 문제, 스트림 불균형, 메모리 전송 병목 등을 정확히 진단했다. 특히, 동일 모델을 다른 GPU에서 실행했을 때 발생하는 메모리 대역폭 한계와 커널 스케줄링 차이를 정량화해, 시스템 설정(예: batch size 조정, 스트림 수 조정) 가이드라인을 제공한다. 논문의 기여는 (1) 대규모 GPU 트레이스를 O(n) 시간·공간으로 처리하는 알고리즘, (2) 딥러닝 반복 구조를 자동으로 식별하는 패턴 마이닝 기법, (3) 실무에서 바로 활용 가능한 시각화 및 진단 보고서 생성 도구, (4) TensorFlow의 GPU 사용 특성을 실증적으로 규명한 점이다. 다만, 현재 구현은 단일 루프 구조에 최적화돼 있어 복합적인 다중 루프 혹은 동적 그래프(예: PyTorch)에는 추가 연구가 필요하다.
댓글 및 학술 토론
Loading comments...
의견 남기기