스택 잔차 LSTM과 학습 가능한 바이어스 디코딩을 활용한 개체명 인식 향상
초록
본 논문은 깊은 RNN 구조에서 발생하는 표현 퇴화 문제를 해결하기 위해 스택형 잔차 연결을 도입하고, 로그우도 기반 학습 모델의 출력에 학습 가능한 퍼센트 바이어스를 적용해 CoNLL‑2003 영어·스페인어 데이터셋에서 최첨단(F‑score) 성능을 달성한 연구이다.
상세 분석
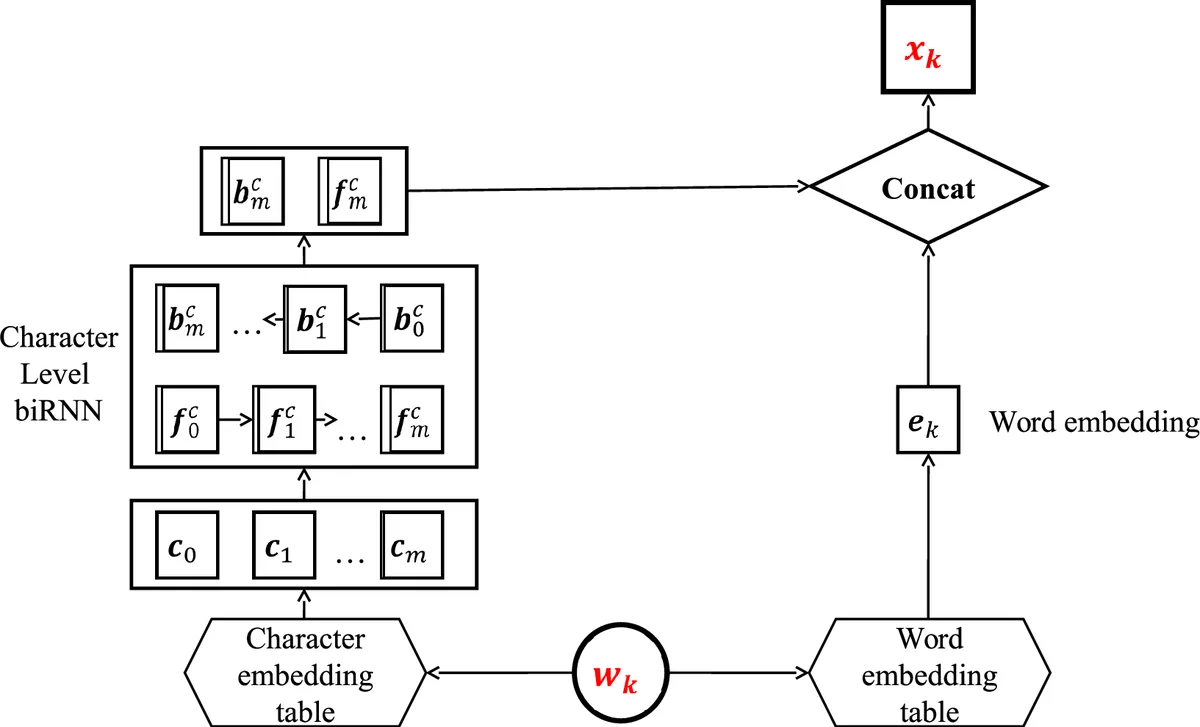
이 연구는 두 가지 핵심 혁신을 제시한다. 첫 번째는 기존의 스택형 RNN에 잔차‑아이덴티티 연결을 변형하여, 하위 레이어의 원본 입력을 상위 레이어의 출력에 연결(concat) 형태로 전달함으로써 차원 제한을 없애고 정보 손실을 최소화한 “스택 잔차 RNN”이다. 이는 He et al. (2016)의 이미지 분야 잔차 네트워크 아이디어를 순환 구조에 맞게 재구성한 것으로, 다층 LSTM을 쌓을 때 발생하는 학습 난이도와 표현 퇴화를 완화한다. 실험에서는 2~4층을 비교했을 때 3층이 가장 높은 F1을 기록했으며, 특히 영어와 스페인어 모두에서 통계적으로 유의미한 개선(p < 0.05)을 보였다.
두 번째 혁신은 바이어스 디코딩이다. 기존 NER 시스템은 토큰‑레벨 로그우도(log‑likelihood)로 학습하지만 평가 지표는 엔티티‑단위 F1이다. 이를 직접 최적화하기 어려운 점을 고려해, Viterbi 디코딩 단계에서 각 라벨에 퍼센트 비율의 가중치(b_y)를 더하는 간단한 조정을 도입한다. 초기 실험에서는 ‘O’ 라벨에 1.1의 바이어스를 적용해 테스트 F1을 91.07→91.22로 끌어올렸다. 이후 바이어스를 모든 라벨에 대한 파라미터로 확장하고, 외부 평가 스크립트 기반 F1을 목표 손실(log 2(1‑F1/100))로 정의해 수치적 미분(central difference)으로 그래디언트를 근사한다. 이 과정은 SGD와 동일한 절차로 학습되며, 바이어스 파라미터 수는 라벨 수와 동일해 과도한 파라미터 증가 없이 성능을 미세 조정한다.
추가 실험에서는 사전학습된 언어 모델(LM) 임베딩을 앞·뒤 방향으로 결합했지만, 영어에서는 약간의 이득을 보였으나 스페인어에서는 성능 저하를 야기했다. 이는 LM 임베딩이 언어마다 문맥 정보를 제공하는 방식이 다를 수 있음을 시사한다. 전체적으로 스택 잔차 RNN과 바이어스 디코딩을 결합한 모델이 기존 최고 성능을 앞서며, 특히 바이어스 디코딩은 로그우도 기반 모델이 놓치는 엔티티‑수준 최적화를 가능하게 한다는 점이 가장 큰 기여이다.
한계점으로는 바이어스 파라미터 학습 시 수치 미분에 의존해 계산 비용이 증가하고, 하이퍼파라미터 ε와 학습률에 민감하다는 점이다. 또한 LM 임베딩의 효과가 언어마다 상이하므로, 다국어 적용 시 별도의 튜닝이 필요하다. 향후 연구에서는 미분 가능한 근사 F1 손실을 직접 모델에 통합하거나, Transformer 기반 인코더와 결합해 잔차 연결의 일반성을 검증할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기