협동 커널: GPU 차단 알고리즘을 위한 공정 스케줄링과 멀티태스킹
초록
GPU에서 차단(Blocking) 알고리즘을 실행하려면 워크그룹 간의 공정한 스케줄링이 필수이다. 기존 OpenCL·CUDA 모델은 이를 보장하지 않으며, 현재 드라이버는 점유 기반(occupancy‑bound) 실행을 사용해 공정성을 우연히 얻는다. 저자들은 “협동 커널(cooperative kernels)”이라는 확장을 제안한다. 프로그래머는 over_kill과 request_fork 두 원시 함수를 삽입해 스케줄러와 협력하고, 스케줄러는 워크그룹을 공정하게 배치·해제한다. 구현은 OpenCL 2.0 위에 순수 소프트웨어로 이루어졌으며, 그래프 탐색·워크스틸링 등 대표적인 불규칙 데이터‑병렬 알고리즘에 적용해 멀티태스킹 성능을 평가한다.
상세 분석
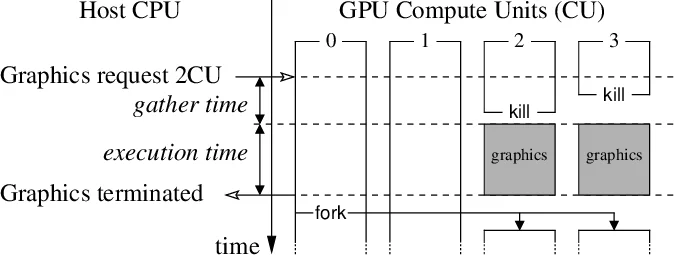
이 논문은 GPU에서 차단 동기화가 필요한 불규칙 데이터‑병렬 알고리즘이 직면한 근본적인 스케줄링 문제를 정확히 짚어낸다. 현재 OpenCL·CUDA 표준은 워크그룹 간 공정성을 명시적으로 보장하지 않으며, 실제 하드웨어는 ‘점유 기반 실행(occupancy‑bound)’이라는 암묵적 모델에 의존한다. 이 모델에서는 워크그룹이 한 번 컴퓨트 유닛에 할당되면 그 유닛을 독점적으로 사용해 종료될 때까지 다른 워크그룹이 전혀 스케줄되지 않는다. 따라서 워크그룹 수가 컴퓨트 유닛 수를 초과하면 새로운 워크그룹은 대기 상태에 머무르게 되고, 이는 전역 장벽이나 뮤텍스와 같은 차단 연산이 영원히 대기하게 만드는 원인이 된다.
저자들은 이러한 상황을 해결하기 위해 ‘협동 커널’이라는 프로그래밍 모델을 제안한다. 핵심은 두 가지 새로운 언어 원시 함수, over_kill과 request_fork이다. over_kill은 현재 워크그룹이 스스로를 스케줄러에 “희생”하도록 요청한다. 스케줄러는 이를 받아들여 워크그룹을 즉시 중단시키고, 다른 고우선순위 작업(예: 그래픽 렌더링)에게 자원을 양보한다. 반대로 request_fork는 커널이 추가 워크그룹을 필요로 할 때 호출한다. 스케줄러는 가능한 경우 즉시 새로운 워크그룹을 할당하여 병렬성을 회복한다. 이러한 호출은 명시적인 ‘프리엠션 포인트’를 제공함으로써, 전통적인 프리엠션(선점) 방식이 요구하는 전체 레지스터·캐시 상태 저장 비용을 회피한다.
스케줄러와 커널 간 계약(contract)은 다음과 같다. (1) 워크그룹은 over_kill을 충분히 자주 호출해야 하며, 이는 실시간 그래픽 프레임 레이트와 같은 소프트‑실시간 제약을 만족시키기 위함이다. (2) 스케줄러는 현재 실행 중인 협동 커널의 워크그룹을 공정하게 스케줄링한다—즉, 현재 할당된 워크그룹들 간에 선점 없이 동등하게 실행된다. (3) request_fork가 호출될 때 스케줄러는 가능한 한 빨리 추가 워크그룹을 제공한다.
구현 측면에서 저자들은 OpenCL 2.0의 기존 기능만을 사용해 프로토타입을 구축했다. over_kill은 워크그룹이 현재 수행 중인 커널을 종료하고, 호스트가 관리하는 워크그룹 풀에 반환하는 형태로 구현되었다. request_fork는 호스트가 미리 할당해 둔 워크그룹 풀에서 새로운 워크그룹을 선택해 커널에 전달한다. 이 과정에서 어떠한 하드웨어 전용 프리엠션 메커니즘도 사용되지 않으며, 따라서 현재 상용 GPU에서 바로 실행 가능하다.
평가에서는 워크스틸링 큐와 프론티어 기반 그래프 탐색 두 대표적인 차단 알고리즘을 포팅했다. 실험 결과, 협동 커널은 동일한 워크그룹 수를 사용했을 때 기존 점유 기반 실행과 거의 동일한 성능을 보였으며, 동시에 그래픽 작업과의 멀티태스킹 상황에서도 그래픽 프레임 레이트가 크게 저하되지 않았다. 특히, over_kill에 의해 워크그룹이 해제되는 ‘gather time’이 수십 마이크로초 수준으로 짧아, 실시간 요구사항을 만족시킬 수 있음을 확인했다. 또한, Nvidia Pascal GPU의 하드웨어 프리엠션을 활용한 최적 구현과 비교했을 때, 소프트웨어 기반 협동 커널이 80 % 이상 효율을 유지함을 보여, 하드웨어 지원이 없어도 실용적인 성능을 달성할 수 있음을 증명했다.
논문의 의의는 크게 세 가지이다. 첫째, 차단 알고리즘을 위한 공정 스케줄링을 언어 수준에서 명시적으로 제공함으로써, 미래 GPU가 점유 기반 실행을 포기하더라도 안정적인 실행을 보장한다. 둘째, 기존 비협동 커널에 영향을 주지 않으며, 기존 코드에 최소한의 over_kill·request_fork 삽입만으로 전환이 가능하다는 점에서 실용성이 높다. 셋째, 하드웨어 프리엠션이 도입될 경우에도 이 모델은 ‘스마트 프리엠션 포인트’를 제공해 불필요한 상태 저장을 최소화할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기