진화적 합성을 통한 신경망 정밀도 제한의 효율성 탐구
초록
본 연구는 진화적 딥 인텔리전스 프레임워크에 신경돌기(시냅스) 정밀도 제한을 도입하여, 16비트 반정밀도 가중치를 적용한 후 세대별 진화를 진행한다. 실험 결과, GoogLeNet 기반 DetectNet을 대상으로 한 객체 검출에서 시냅스 수가 10배 감소하고 추론 속도가 5배 이상 향상되었으며, 정확도는 유지되는 것을 확인하였다.
상세 분석
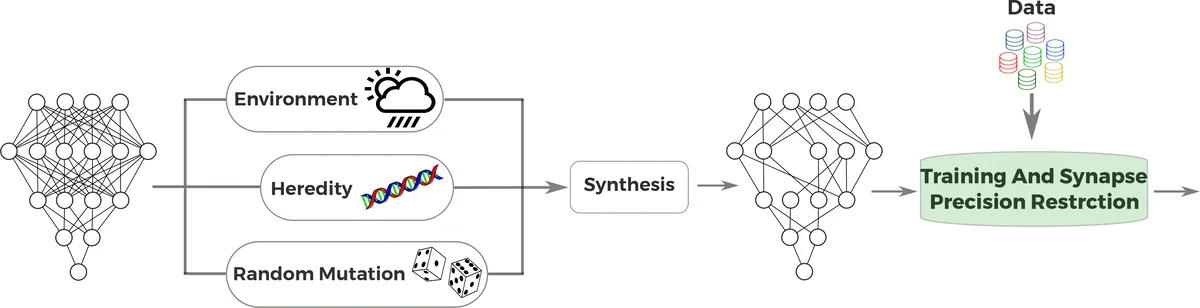
본 논문은 기존 딥 뉴럴 네트워크(DNN)의 규모와 깊이가 증가함에 따라 발생하는 연산·메모리·에너지 비용을 완화하기 위한 새로운 접근법을 제시한다. 핵심 아이디어는 ‘진화적 합성(evolutionary synthesis)’이라는 확률적 유전 모델링 전략을 이용해, 이전 세대의 시냅스 확률 분포를 ‘DNA’로 삼아 새로운 세대를 무작위 변이와 자연 선택 방식으로 생성하는 것이다. 구체적으로, 각 세대 g의 네트워크 구조 S_g는 이전 세대의 가중치 W_{g‑1}에 조건부 확률 P(S_g|W_{g‑1}) 로 정의되며, 환경 요인 F(α)와 결합해 최종 합성 확률 P(S_g)≈P(S_g|W_{g‑1})·F(α) 를 만든다. 여기서 F(α)는 메모리·연산 제한, 에너지 제약 등 목표 환경을 수치화한 파라미터이다.
연구진은 이 프레임워크에 ‘시냅스 정밀도 제한(synaptic precision restriction)’을 추가한다. 각 세대에서 학습은 32비트 전밀도(Full‑Precision)로 수행한 뒤, 학습이 끝난 가중치를 16비트 반정밀도(half‑precision)로 강제 변환한다. 이렇게 변환된 가중치는 다음 세대의 DNA가 되며, 시냅스 수 자체도 환경 요인에 의해 점진적으로 감소하도록 설계된다. 즉, 정밀도 감소가 네트워크 구조의 희소화와 상호 보완적으로 작용해 전체 연산량을 크게 줄인다.
실험은 NVIDIA Jetson TX1 보드 위에서 Caffe와 TensorRT를 이용해 Parse‑27k 객체 검출 데이터셋을 대상으로 수행되었다. 기본 모델은 GoogLeNet 기반 DetectNet이며, 13세대에 걸쳐 진화 과정을 적용하였다. 결과는 두 축으로 나타난다. 첫째, 시냅스 수는 초기 대비 약 10배 감소했으며, 이는 모델 파라미터와 메모리 요구량을 크게 낮춘다. 둘째, 추론 속도는 7 fps에서 37 fps로 5배 이상 향상되었다. 정밀도와 재현율을 측정한 결과, 전체 세대에 걸쳐 정확도는 거의 변하지 않았으며, 초기 대비 약 2 % 정도의 미세한 변동만 보였다. 이는 정밀도 제한이 모델 성능에 미치는 부정적 영향을 최소화하면서도 효율성을 크게 높일 수 있음을 시사한다.
이 접근법의 장점은 (1) 전통적인 진화 알고리즘에서 요구되는 복잡한 교배·돌연변이 연산을 확률적 샘플링으로 대체해 구현이 간단하고, (2) 하드웨어 친화적인 정밀도 제한을 자연스럽게 통합해 실제 임베디드 시스템에 바로 적용 가능하다는 점이다. 반면, 현재는 시냅스 정밀도를 16비트로 고정했으며, 보다 낮은 비트폭(8비트 이하)이나 비정형 양자화에 대한 탐색은 부족하다. 또한, 현재 실험은 단일 객체 검출 태스크에 국한되어 있어, 이미지 분류·시계열·자연어 처리 등 다양한 도메인에 대한 일반화 가능성은 추가 검증이 필요하다.
향후 연구는 (가) 비트폭을 가변적으로 조정하는 다중 정밀도 스케줄링, (나) 시냅스 연결 구조 자체를 진화시키는 토폴로지 최적화, (다) 에너지 소비를 직접 측정해 환경 요인 F(α)를 보다 정량화하는 방법론 개발 등을 포함한다. 이러한 확장은 진화적 합성 프레임워크를 더욱 강력한 경량화 도구로 만들며, 자원 제한 환경에서의 AI 적용을 가속화할 것으로 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기