대규모 마진을 갖는 딥 뉴럴 네트워크의 일반화 이론
본 논문은 딥 뉴럴 네트워크(DNN)의 일반화 오차를 분류 마진과 네트워크의 야코비안 스펙트럼 노름을 통해 분석한다. 깊이와 폭에 무관하게 학습 샘플 주변에서 야코비안의 스펙트럼 노름이 제한되면 일반화 오차가 작아진다는 이론적 근거를 제시하고, 배치 정규화와 가중치 정규화가 이러한 조건을 자연스럽게 만족함을 설명한다. 또한 야코비안 기반 정규화 기법을 도입하고, MNIST·CIFAR‑10·ImageNet 등에서 실험적으로 검증한다.
저자: Jure Sokolic, Raja Giryes, Guillermo Sapiro
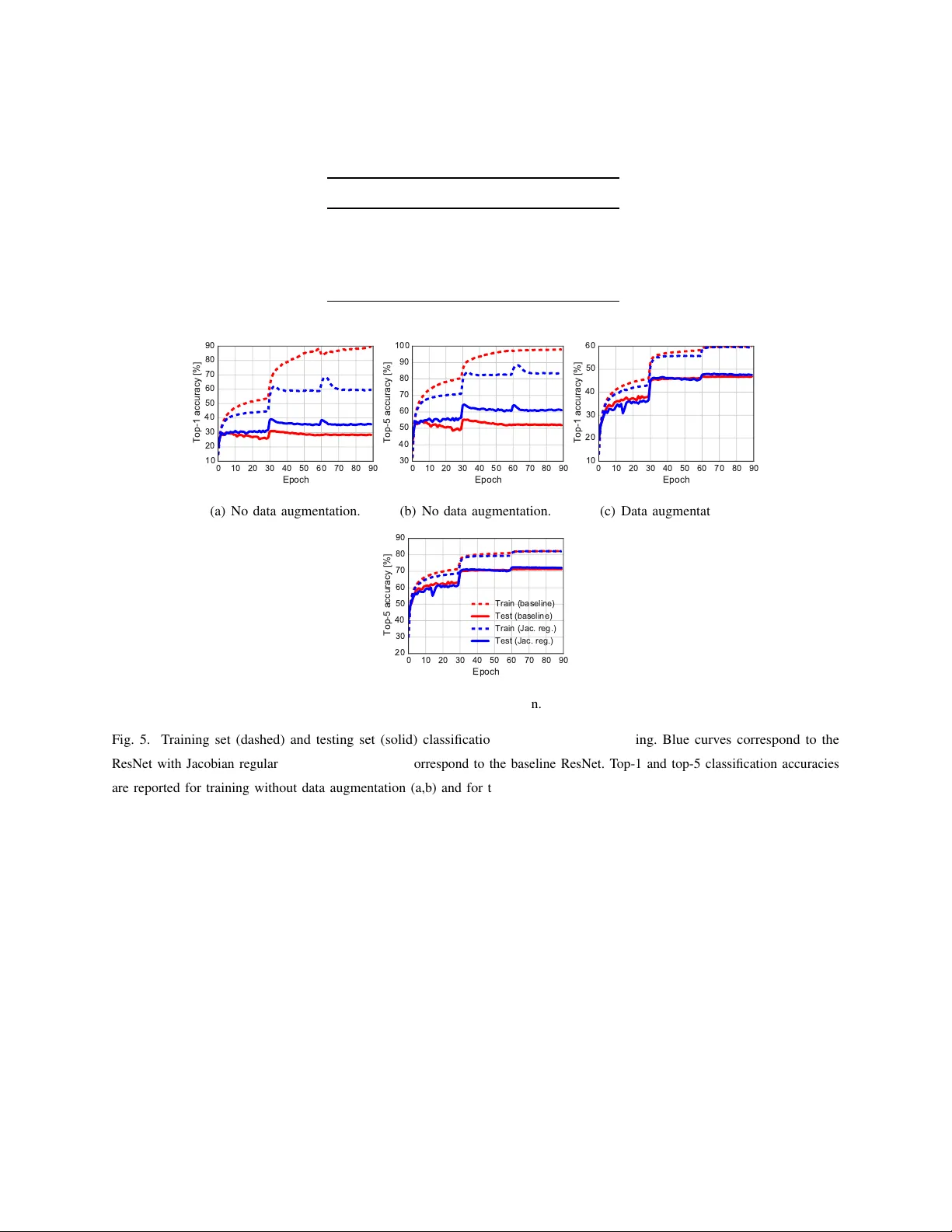
본 논문은 딥 뉴럴 네트워크(DNN)의 일반화 오차를 분류 마진(classification margin)과 네트워크의 야코비안(Jacobian) 행렬의 스펙트럼 노름을 중심으로 새롭게 분석한다. 서론에서는 DNN이 이미지·음성 인식 등 다양한 분야에서 뛰어난 성능을 보이고 있지만, 기존 이론은 네트워크의 깊이·폭이 증가함에 따라 일반화 오차가 지수적으로 커진다고 예측한다는 점을 지적한다. 실제 실험에서는 오히려 깊고 넓은 네트워크가 더 낮은 일반화 오차를 보이는 역설적인 현상이 관찰된다. 이를 해결하기 위해 저자들은 데이터 구조를 고려한 “알고리즘적 강건성” 프레임워크를 채택한다.
**1. 문제 정의와 강건성 프레임워크**
학습 샘플 집합 Sₘ을 이용해 0‑1 손실을 정의하고, 일반화 오차 GE = |ℓ_exp – ℓ_emp| 로 측정한다. 알고리즘적 강건성(Definition 1)은 샘플 공간을 K개의 비겹치는 집합으로 분할하고, 같은 집합에 속한 샘플들의 손실 차이가 ε 이하일 때 (K, ε)‑강건하다고 정의한다. 이때 Theorem 1에 의해 GE ≤ ε + O(√(K/m)) 가 성립한다. K는 입력 공간 X의 커버링 넘버 N(X; d, ρ)와 라벨 수 N_Y에 의해 결정된다.
**2. 분류 마진과 야코비안의 연결**
분류 마진 γ_d(s_i) (Definition 2)는 훈련 샘플 s_i를 중심으로 가장 큰 반경 ρ를 찾는 것으로, 그 안의 모든 점이 동일한 클래스로 예측되는지를 측정한다. 마진이 클수록 모델은 입력 변동에 강건하다. 저자들은 연속성에 대한 Lipschitz 상수로서 야코비안 스펙트럼 노름 ‖J_f(x)‖₂를 도입한다. 구체적으로,
γ ≥ 1 / sup_{x∈B(x_i, ρ)} ‖J_f(x)‖₂
라는 하한을 증명한다. 이는 야코비안이 작을수록 마진이 커지고, 따라서 일반화 오차가 작아진다는 직관과 일치한다.
**3. 깊이·폭 독립적인 일반화 보장**
기존 연구(
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기