웹 검색에서의 합리적 부인 가능성 탐지와 평가
초록
본 논문은 사용자가 민감한 주제에 대한 검색 기록을 숨기고 “합리적으로 부인”할 수 있는지를 판단하는 도구 PDE를 제안한다. 검색 엔진이 광고·추천을 통해 사용자의 관심을 학습하는 과정을 검증하고, 무작위 잡음 쿼리·클릭 교란이 효과가 제한적임을 보인다. 대신 사용자가 관심 없는 상업적 “프록시 토픽”을 의도적으로 검색하도록 유도하면, 민감 주제에 대한 학습을 크게 억제할 수 있음을 실험적으로 확인한다.
상세 분석
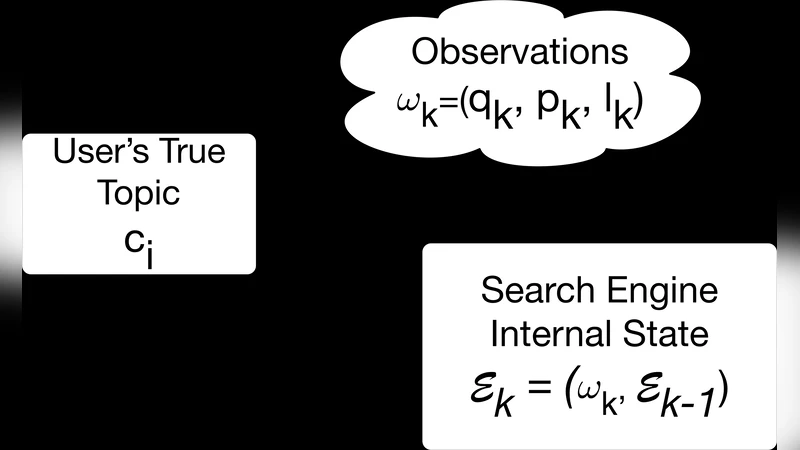
이 논문은 “합리적 부인 가능성(plausible deniability)”을 “확률적 균형”이라는 정의 아래 정량화한다. 구체적으로, 사용자가 여러 주제 C 중 하나에 관심이 있을 확률을 검색 엔진이 추정하도록 하고, 민감 주제 c_i 에 대한 추정 확률 p_i 가 다른 주제에 대한 확률 p_j 보다 현저히 높을 경우 부인 가능성이 손상된다고 판단한다. 이를 구현하기 위해 저자들은 ‘프로브 쿼리’를 사전에 정의하고, 일정 간격으로 실제 사용자 쿼리 사이에 삽입한다. 프로브 쿼리의 검색 결과 페이지에 나타나는 광고·추천을 관찰함으로써, 검색 엔진이 내부 상태 E_k 를 어떻게 업데이트하는지를 블랙박스 방식으로 추정한다.
핵심 기술은 PDE(Plausible Deniability Estimator)이다. PDE는 각 프로브 쿼리마다 관측된 광고 카테고리를 토픽 매핑 테이블과 비교해 X̄ (관심 여부) 의 베이즈 사후 확률 d_i 를 계산한다. 이 확률값을 누적해 세션 전체에 걸친 P(민감 주제|관찰) 을 추정하고, “균형 확률” 기준을 초과하면 경고를 발생한다. 실험에서는 3~5개의 민감 쿼리만으로도 100 %의 주제에 대해 p_i > 0.5 를 달성했으며, 특히 건강·성적 선호와 같은 주제는 p_i ≈ 0.9 까지 상승했다.
방어 메커니즘으로는 두 가지가 시험되었다. 첫 번째는 무작위 잡음 쿼리와 클릭 교란을 삽입하는 전통적 혼란 기법이다. 저자들은 잡음 비율을 1:1부터 10:1까지 다양하게 조정했지만, 검색 엔진이 짧은 시간 안에 핵심 토픽을 재학습해 p_i 를 다시 높이는 모습을 관찰했다. 즉, 잡음 기반 방어는 단일 쿼리 수준에서는 효과적이지만, 세션 전체에서는 지속적인 위협을 완화하지 못한다.
두 번째는 “프록시 토픽” 방어이다. 여기서는 사용자가 실제 관심 없는 상업적·일반적 주제(예: 가전제품, 여행) 를 의도적으로 검색하게 하여, 검색 엔진이 학습하는 토픽을 해당 프록시로 전환하도록 유도한다. 실험 결과, 프록시 토픽을 70 % 이상의 비율로 삽입했을 때 민감 주제에 대한 사후 확률 p_i 가 0.2 이하로 급격히 감소했으며, 부인 가능성 경고가 거의 발생하지 않았다. 이는 검색 엔진이 “주제 학습 속도”가 빠른 점을 역이용해, 관심을 다른 주제로 전환시키는 전략이 효과적임을 보여준다.
또한 논문은 검색 엔진이 광고·추천 외에 “Top Stories”, “Related Tweets” 등 추가 개인화 요소를 활용할 가능성을 언급하며, 향후 연구에서 이러한 신호까지 포함한 다중 채널 분석이 필요함을 제시한다. 전체적으로 이 연구는 블랙박스 관측, 베이즈 추정, 그리고 실용적인 방어 설계라는 세 축을 결합해, 사용자가 자신의 검색 프라이버시를 정량적으로 모니터링하고 관리할 수 있는 실용적 프레임워크를 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기