커널 풀링 기반 엔드투엔드 문서 순위 모델 KNRM
초록
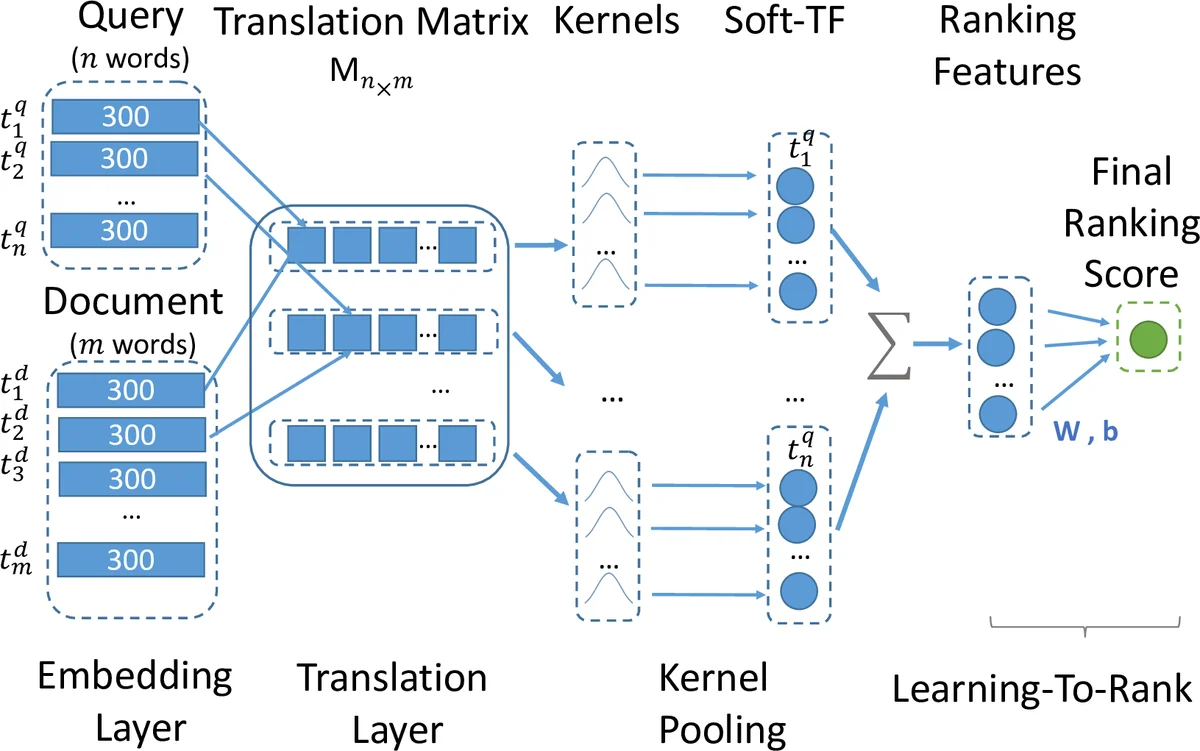
KNRM은 단어 임베딩을 이용해 쿼리와 문서 사이의 유사도 행렬을 만든 뒤, 다중 RBF 커널을 통해 소프트 매치 빈도를 추출하고, 이를 학습‑to‑rank 레이어에 입력해 최종 순위 점수를 산출한다. 전체 파이프라인을 end‑to‑end로 학습함으로써 검색 특화 임베딩과 다층 소프트 매치를 동시에 최적화한다.
상세 분석
KNRM은 기존의 정확 매치 기반 BM25와 달리, 단어 수준의 연속적 유사도를 활용한다. 먼저 입력된 쿼리와 문서 토큰을 L 차원의 임베딩 벡터로 변환하고, 코사인 유사도로 구성된 번역 행렬 M을 만든다. 이 행렬의 각 행은 하나의 쿼리 단어와 모든 문서 단어 사이의 유사도를 담고 있다. 핵심은 RBF 커널 풀링 단계이다. μ와 σ 파라미터를 가진 K개의 가우시안 커널을 M의 각 행에 적용해, 특정 유사도 구간(예: 정확 매치, 약한 의미 매치 등)에 속하는 단어 쌍의 “소프트 TF”를 로그합 형태로 집계한다. 이렇게 얻어진 K‑차원 피처 벡터 ϕ(M)는 순위 레이어에 전달돼 tanh( wᵀϕ + b ) 형태의 점수로 변환된다.
학습은 쌍별 랭킹 손실(hinge loss)을 사용한다. 손실 미분은 순위 레이어 → 커널 풀링 → 번역 행렬 → 임베딩 순으로 역전파된다. 특히 커널은 각 μ에 가까운 유사도 값을 끌어당기거나 멀어지게 하는 “힘”을 제공해, 임베딩이 검색 의도에 맞는 다중 수준 매치를 생성하도록 유도한다. 이는 기존의 고정된 사전학습 임베딩과 달리, 검색 로그 기반 클릭 데이터를 통해 직접 최적화된 검색‑특화 임베딩을 얻는 메커니즘이다.
실험은 대규모 중국어 검색 엔진 로그(35M 세션, 96K 쿼리)를 사용했으며, 헤드·테일·크로스‑도메인 등 다양한 평가 시나리오에서 BM25, DSSM, CDSSM, DRMM 등 최신 베이스라인을 크게 앞섰다(최대 65% NDCG 향상). 분석 결과, 커널 수를 줄이거나 임베딩 업데이트를 비활성화하면 성능이 급격히 떨어지는 반면, 커널‑가이드 임베딩 학습을 유지하면 소프트 매치가 효과적으로 강화되어 일반화가 향상된다.
KNRM의 장점은 (1) 파라미터 효율성 – 전체 어휘에 대해 |V|·L 개의 임베딩만 필요, (2) 차별화된 소프트 매치 피처 제공 – 다중 RBF 커널이 다양한 의미 거리대를 동시에 포착, (3) 엔드‑투‑엔드 학습으로 검색 목적에 맞는 임베딩을 자동 생성한다는 점이다. 한계로는 커널 파라미터(μ, σ)의 사전 설정이 성능에 민감하고, 매우 긴 문서에 대해 행렬 크기가 커져 메모리·연산 비용이 증가한다는 점을 들 수 있다. 향후 연구에서는 동적 커널 파라미터 학습, 효율적인 행렬 압축, 그리고 멀티‑모달(텍스트·이미지) 확장 등이 제안될 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기