THUMT 차세대 신경기계 번역을 위한 오픈소스 툴킷
초록
THUMT는 Theano 기반의 주의(attention) 기반 인코더‑디코더 모델을 구현한 오픈소스 NMT 툴킷이다. 최대우도추정(MLE), 최소위험학습(MRT), 반지도학습(SST)이라는 세 가지 학습 기준과 SGD, Adadelta, Adam 최적화를 지원한다. 시각화 도구를 통해 은닉 상태와 입력 단어 간의 연관성을 LRP 기법으로 보여주며, 중국어‑영어 실험에서 MRT 적용 시 기존 GroundHog 대비 BLEU 점수가 크게 향상됨을 보고한다.
상세 분석
THUMT는 기존의 attention‑based NMT 모델을 그대로 채택하면서도 학습 단계에서 세 가지 서로 다른 목표 함수를 제공한다는 점이 가장 큰 특징이다. 첫 번째인 최대우도추정(MLE)은 전통적인 교차 엔트로피 손실을 최소화하여 모델 파라미터를 추정한다. 이는 빠른 수렴과 안정적인 초기 모델을 제공하지만, 평가 지표와 직접적인 연관성이 부족해 실제 번역 품질 향상에 한계가 있다. 두 번째인 최소위험학습(MRT)은 기대 손실을 직접 최소화한다. 여기서 기대 손실은 BLEU와 같은 평가 지표를 손실 함수로 사용해, 학습 과정에서 모델이 실제 번역 품질을 직접 최적화하도록 만든다. 논문에서는 MLE로 사전 학습된 모델을 초기값으로 사용하고, 이후 MRT를 적용해 BLEU 점수가 평균 35% 상승함을 확인했다. 세 번째인 반지도학습(SST)은 대규모 단일언어 코퍼스를 활용해 소스‑타깃, 타깃‑소스 양방향 모델을 동시에 학습한다. 이는 저자원 언어쌍에서 특히 효과적이며, 실험에서는 monolingual 데이터만을 이용한 경우에도 BLEU 점수가 23% 상승하는 결과를 보였다.
최적화 측면에서는 SGD, Adadelta, Adam 세 가지를 지원한다. 특히 Adam은 각 파라미터마다 학습률을 자동 조정해 빠른 수렴을 가능하게 하는데, THUMT는 NaN 발생 문제를 해결하기 위해 Adam의 epsilon 값을 조정하고, 학습률 스케줄을 세밀하게 설정했다. 실험 결과는 Adam이 Adadelta보다 10배 이상 빠른 학습 시간을 보이며, 최종 BLEU 점수에서도 일관된 우위를 점했다.
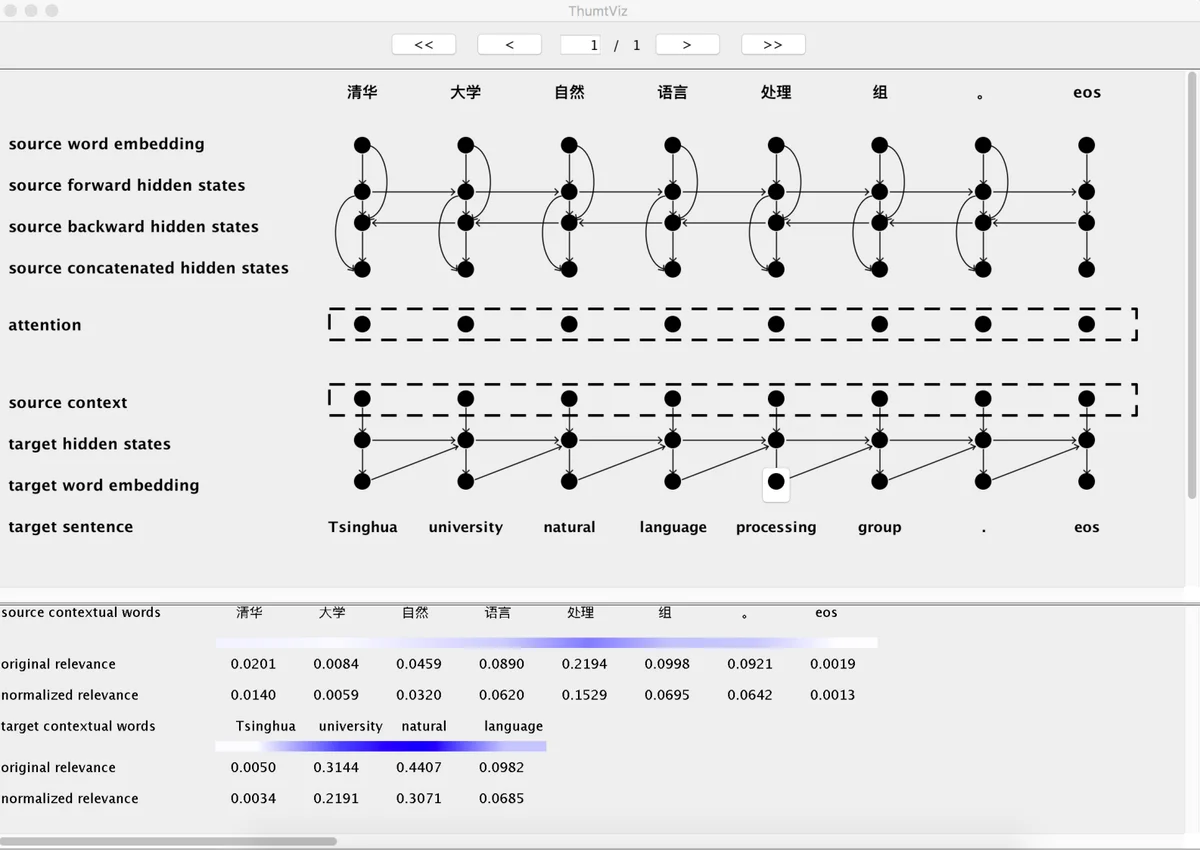
시각화 도구는 LRP(Layer‑wise Relevance Propagation)를 적용해 은닉 상태와 입력 토큰 간의 기여도를 정량화한다. 사용자는 특정 출력 토큰을 클릭하면 해당 토큰에 가장 큰 영향을 미친 소스와 타깃 단어를 색상 강도로 확인할 수 있다. 이는 “블랙박스”인 NMT 모델의 내부 작동을 직관적으로 이해하는 데 큰 도움이 된다.
알려지지 않은 단어(UNK) 처리에서는 FastAlign 기반의 양방향 정렬 사전을 구축해, UNK 토큰을 원문에 가장 높은 정렬 확률을 가진 단어로 대체한다. 이 방법은 모든 학습 기준과 최적화 조합에서 평균 0.5~1.0 BLEU 점수 향상을 가져왔다.
실험은 1.25M 중국어‑영어 병렬 코퍼스와 대규모 단일언어 코퍼스를 사용했으며, 동일한 하이퍼파라미터(임베딩 620, 은닉 1000, 배치 80, 빔 10)를 적용해 GroundHog과 직접 비교했다. 결과는 MLE 기준에서는 두 툴킷이 비슷한 성능을 보였지만, MRT 적용 시 THUMT가 35 BLEU 포인트, SST 적용 시 24 BLEU 포인트 상승했다. 또한, Adam 최적화와 결합했을 때 학습 시간은 MLE‑Adam 10시간, MRT‑Adam 72시간으로, MRT가 비용이 많이 들지만 품질 향상이 확연히 나타난다.
전반적으로 THUMT는 학습 목표 함수의 다양화, 최적화 안정성 강화, 시각화 지원을 통해 연구자와 개발자에게 NMT 모델을 보다 깊이 있게 탐구하고 실용적인 성능을 끌어올릴 수 있는 플랫폼을 제공한다. 다만 현재는 단일 GPU만 지원하고, MRT 구현이 메모리와 시간 소모가 크다는 점이 향후 개선 과제로 남는다.
댓글 및 학술 토론
Loading comments...
의견 남기기