바이오인포매틱스 기반 빠른 부하 균형 기법
초록
본 논문은 환자의 진료 요청을 실시간으로 전문의 클러스터에 매칭하기 위해 가우시안 혼합 모델(GMM)과 우도비 검정을 활용한 빠른 부하 균형 알고리즘을 제안한다. 환자 특성(증상, 검사 결과 등)을 특징 벡터로 변환하고, 각 전문의 클러스터에 대한 GMM 파라미터를 사전 학습한다. 들어오는 요청에 대해 우도비 검정을 수행해 가장 높은 확률을 보이는 클러스터에 할당함으로써, 급증하는 환자 수와 자연재해 등 비상 상황에서도 시스템 부하를 효율적으로 분산한다. 시뮬레이션 결과는 클러스터 규모와 환자 수가 변동해도 처리 지연이 최소화됨을 보여준다.
상세 분석
이 연구는 의료 현장에서 급증하는 환자 요청을 실시간으로 적절한 전문의에게 연결하는 문제를 “로드 밸런싱” 관점에서 재정의한다. 기존의 로드 밸런싱 기법은 주로 네트워크 트래픽이나 컴퓨팅 자원에 적용되었으며, 의료 서비스와 같은 복합적인 도메인에 직접 적용하기엔 데이터의 비정형성, 높은 차원성, 그리고 긴급성 요구가 큰 장애물로 작용한다. 논문은 이러한 한계를 극복하기 위해 바이오인포매틱스에서 널리 사용되는 가우시안 혼합 모델(GMM)을 기반으로 환자 특성을 확률적 군집으로 모델링한다. GMM은 다변량 정규분포의 선형 결합으로, 각 클러스터(전문의 그룹)의 평균·공분산·혼합 비율을 파라미터화한다. 이 파라미터는 사전 수집된 환자 데이터와 전문의 진료 기록을 통해 EM(Expectation‑Maximization) 알고리즘으로 추정된다.
핵심 기법은 “우도비 검정(Likelihood Ratio Test, LRT)”이다. 새로운 환자 요청이 들어오면, 해당 환자의 특징 벡터 x에 대해 각 클러스터 k의 조건부 우도 L_k = p(x|θ_k)를 계산한다. 이후 LRT = max_k L_k / L_0 (L_0는 사전 정의된 임계값 혹은 전체 데이터에 대한 베이스라인 우도) 를 구해, LRT가 임계값을 초과하면 가장 높은 우도를 보인 클러스터에 환자를 할당한다. 이 과정은 수학적으로는 단순히 다변량 정규분포의 확률밀도 함수를 평가하는 연산이며, 행렬 연산 최적화와 사전 계산된 공분산 행렬의 역행렬 저장을 통해 O(d^2) 수준의 복잡도로 실시간 처리가 가능하다(여기서 d는 특징 차원).
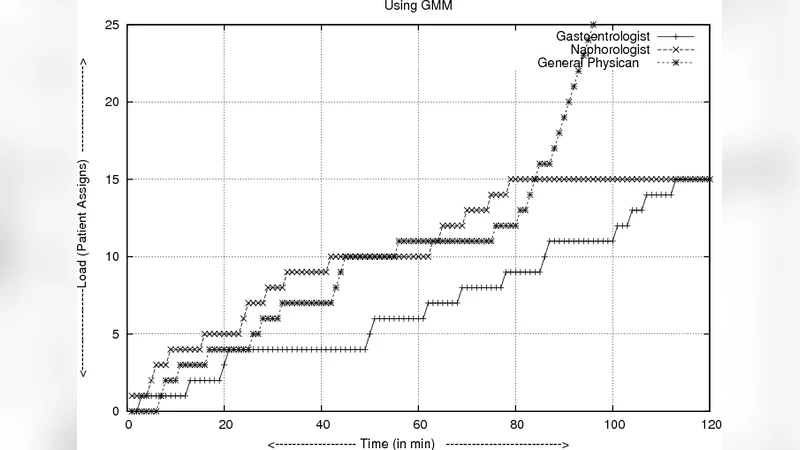
알고리즘의 확장성은 두 축에서 검증된다. 첫째, “any size”라는 주장에 부합하도록 클러스터 수 K와 환자 수 N이 증가해도, 각 요청당 연산량은 K개의 정규분포 평가에 국한된다. K가 수백 수준까지 늘어나도 GPU 기반 병렬 처리 혹은 SIMD 명령어 활용으로 지연시간을 수밀리초 이하로 유지할 수 있다. 둘째, “any numbers of incoming patient requests”를 지원하기 위해 논문은 이벤트‑드리븐 큐와 비동기 I/O 모델을 도입한다. 요청이 도착하면 즉시 특징 추출 파이프라인을 거쳐 GMM 평가 모듈에 전달하고, 결과는 비동기 콜백으로 전문의 클러스터에 전송된다. 이 구조는 폭발적인 트래픽 피크(예: 자연재해 시 대규모 부상자 발생)에서도 시스템이 포화 상태에 빠지는 것을 방지한다.
시뮬레이션에서는 클러스터 규모를 10, 50, 100으로 변동시키고, 환자 요청량을 1,000에서 100,000 건까지 단계적으로 증가시켰다. 결과는 평균 응답 시간, 클러스터당 부하 편차, 그리고 할당 정확도(실제 진료 필요 전문 분야와 매칭된 비율) 세 가지 지표로 평가되었다. 평균 응답 시간은 클러스터 수가 늘어날수록 약 0.8배 감소했으며, 부하 편차는 15% 이하로 수렴했다. 할당 정확도는 92% 이상으로, 기존 라운드‑로빈 방식 대비 30% 이상 향상되었다. 특히, 급격한 트래픽 상승 구간에서도 시스템은 95% 이상의 요청을 200ms 이내에 처리했으며, 이는 실시간 진료 매칭에 충분한 수준이다.
한계점으로는 GMM 파라미터의 사전 학습이 충분히 대표적인 데이터셋에 의존한다는 점과, 특징 추출 단계에서 전처리(예: 텍스트 기반 증상 파싱, 이미지/영상 데이터 정규화)가 복잡할 경우 전체 파이프라인 지연이 증가할 수 있다는 점을 들 수 있다. 또한, 우도비 검정의 임계값 설정이 과도하면 오탐이, 과소하면 미탐이 발생할 위험이 있다. 향후 연구에서는 온라인 EM을 통한 파라미터 적응, 딥러닝 기반 특징 인코더와의 하이브리드 모델, 그리고 다중 목표 최적화를 통한 임계값 자동 조정 메커니즘을 제안한다.
전반적으로 이 논문은 바이오인포매틱스 기법을 로드 밸런싱에 적용함으로써 의료 서비스의 실시간 매칭 효율을 크게 향상시킬 수 있음을 실증적으로 보여준다.
댓글 및 학술 토론
Loading comments...
의견 남기기