온라인 인신매매 탐지를 위한 엔터티 해소 파이프라인
초록
본 논문은 백페이지(backpage.com)에서 수집한 5백만 건의 성매매 광고 데이터를 대상으로, 전화번호와 같은 강력한 특징을 프록시 라벨로 활용해 광고 간 출처를 추정하는 엔터티 해소(Entity Resolution) 파이프라인을 제안한다. 정규표현식 기반 정보 추출, 블로킹, 머신러닝 기반 매치 함수 학습, 그리고 규칙 학습을 순차적으로 적용해 인간 매매와 연관된 광고 클러스터를 식별한다. 실험 결과 매치 함수는 낮은 위양성률을 유지하면서 높은 재현율을 보였으며, 최종 클러스터는 공간·시간·텍스트 특성을 통해 인신매매 의심 활동을 효과적으로 드러냈다.
상세 분석
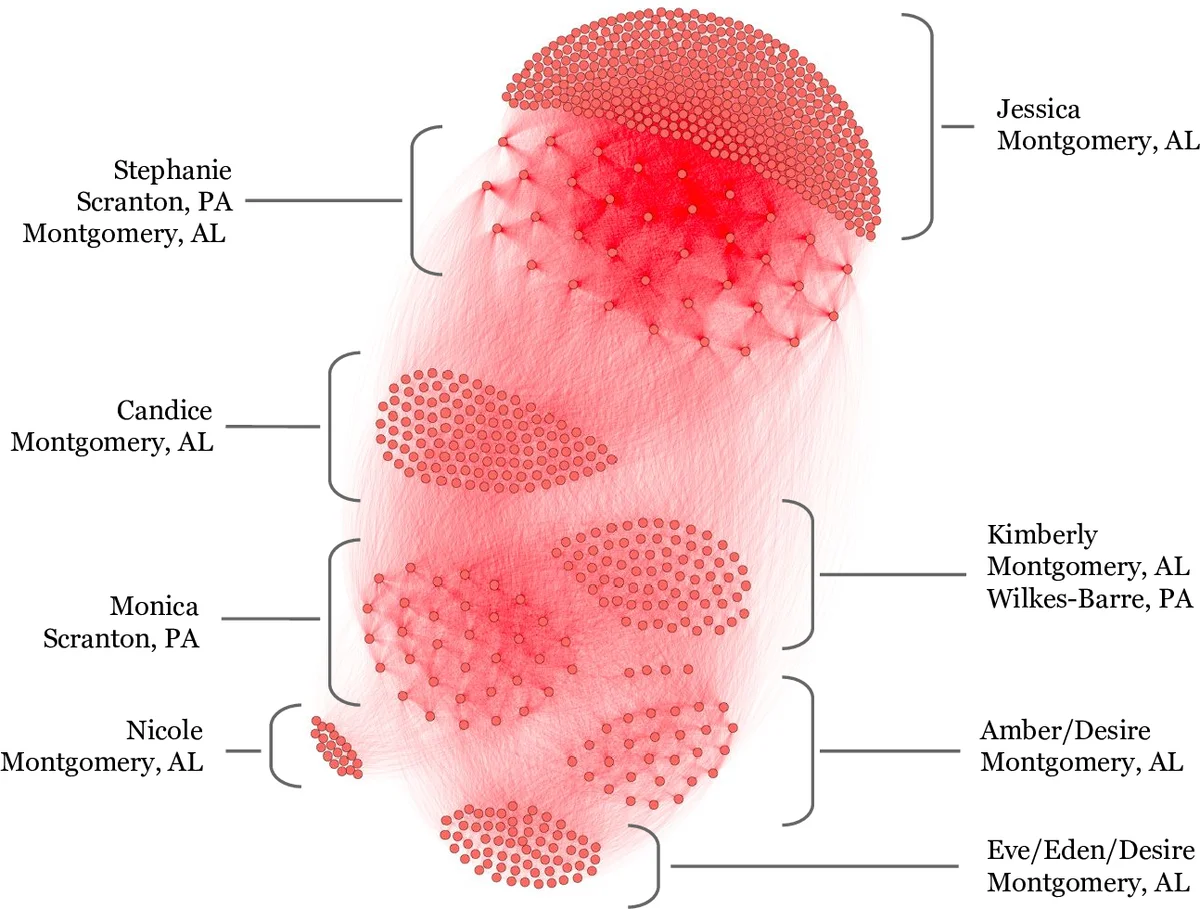
이 연구는 온라인 성매매 광고가 인간 매매와 연결되는 복잡한 네트워크임을 전제로, 기존의 단순 ‘merge‑purge’ 방식이 적용되기 어려운 점을 정확히 짚어낸다. 가장 큰 혁신은 전화번호를 ‘강력 특징(strong feature)’으로 삼아 프록시 라벨을 자동 생성하고, 이를 통해 지도학습용 데이터셋을 구축한 점이다. 전화번호는 광고마다 흔히 변조되거나 다중으로 사용되지만, 동일 번호가 여러 광고에 등장하면 동일 출처일 가능성이 높아, 이를 그래프 G*의 엣지 생성 기준으로 삼았다.
정규표현식 기반 추출기(AnonymousExtractor)는 연령, 비용, 이메일, 인종, 신체 특성 등 15여 개 필드를 높은 정밀도·재현율로 추출한다. 특히 전화번호와 URL은 거의 완벽한 추출(F1 ≈ 0.997)을 보였으며, 이는 프록시 라벨링의 신뢰성을 뒷받침한다. 텍스트는 이모지·오탈자·특수문자 등으로 가득 차 있어 전통적인 토큰 기반 매칭이 어려운데, 연구팀은 Jaccard 유사도와 특수 문자 수, 최장 공통 부분 문자열 등 텍스트 구조적 특성을 추가 피처로 활용했다.
매치 함수 학습 단계에서는 로지스틱 회귀, 나이브 베이즈, 랜덤 포레스트 등 여러 모델을 비교했으며, 랜덤 포레스트가 가장 높은 AUC와 낮은 위양성률을 기록했다. 중요한 피처는 ‘위치(주)’, ‘특수 문자 수’, ‘최장 공통 부분 문자열’, ‘시간 차이’, ‘같은 날 게시 여부’ 등으로, 이는 공간·시간·언어적 연관성이 인간 매매 네트워크를 드러내는 핵심임을 시사한다.
데이터 규모(5 M 레코드) 때문에 전부에 대해 O(N²) 비교는 불가능했다. 이를 해결하기 위해 ‘희귀 단어·희귀 바이그램·희귀 이미지’ 기반 블로킹을 도입했으며, 각 블록 내에서만 전면 비교를 수행한다. 블로킹 규칙은 지원도와 리프트를 기준으로 선택되었고, 실험적으로 블록당 평균 비교 횟수를 10⁴ 수준으로 감소시켰다.
클러스터 수준에서는 300개 이상 광고가 모인 연결 컴포넌트를 대상으로 다시 랜덤 포레스트와 규칙 학습을 적용했다. 최종 모델은 TPR ≈ 90 % (FPR = 1 %)를 달성했으며, 규칙 학습 결과 ‘게시 월·주’, ‘이미지 빈도 표준편차’, ‘이름 수 정규화’ 등이 높은 리프트를 보였다. 이는 인간 매매 조직이 특정 기간에 집중적으로 활동하고, 이미지 재사용 패턴을 보이는 특성을 정량화한 것이다.
한계점으로는 전화번호가 변조되거나 완전히 삭제된 경우 프록시 라벨이 부족해 학습 데이터가 편향될 수 있다. 또한 정규표현식 기반 추출은 새로운 은어·코드워드가 등장하면 즉시 대응하기 어렵다. 향후 딥러닝 기반 텍스트 임베딩과 이미지 메타데이터를 결합한 멀티모달 모델을 도입하면 이러한 약점을 보완할 수 있을 것으로 보인다.
댓글 및 학술 토론
Loading comments...
의견 남기기