과학 논문 추출 요약을 위한 지도 학습 접근법
초록
본 논문은 컴퓨터 과학 분야 10,000편 이상의 논문을 대상으로, 저자 하이라이트를 골드 요약으로 활용한 대규모 추출 요약 데이터셋(CSPubSum·CSPubSumExt)을 구축하고, 문장 임베딩과 8가지 손쉬운 특징을 결합한 모델들을 비교한다. HighlightROUGE와 AbstractROUGE라는 두 개의 자동 라벨링·특징 기법을 제안하고, 문맥을 고려한 신경망 기반 요약기가 기존 베이스라인을 크게 앞선 성능을 보임을 입증한다.
상세 분석
이 연구는 과학 논문 요약이라는 특수 도메인에 초점을 맞추면서, 기존 뉴스 요약에 비해 데이터가 부족한 문제를 데이터 수집 단계부터 해결한다. ScienceDirect에서 제공되는 ‘highlight’ 문장을 골드 요약으로 삼아 10,148편의 논문을 수집했으며, 이를 바탕으로 두 가지 데이터셋을 만든다. CSPubSum은 하이라이트와 무작위로 선택된 하위 10% 문장을 대조군으로 사용해 약 85,000개의 학습 샘플을 제공한다. CSPubSumExt은 HighlightROUGE를 이용해 본문에서 하이라이트와 가장 높은 ROUGE‑L 점수를 갖는 20문장을 추가 라벨링함으로써 학습 샘플을 263,000개까지 확대한다. 이렇게 자동 라벨링을 도입한 이유는 신경망 기반 요약 모델이 대량의 학습 데이터에 의존한다는 점을 감안한 것이다.
모델 설계에서는 문장을 두 가지 방식으로 인코딩한다. 첫째는 평균 Word2Vec 임베딩을 사용한 간단한 벡터 표현, 둘째는 양방향 LSTM을 통한 순차적 인코딩이다. 이와 별도로 8가지 손쉬운 특징(예: AbstractROUGE, 섹션 위치, 숫자 개수, 제목·키워드 겹침, TF‑IDF, 문장 길이 등)을 추가해 로컬·글로벌 컨텍스트를 보완한다. 특징만을 이용한 선형 모델부터, 특징+워드 임베딩, 특징+문장 임베딩, 그리고 이들을 앙상블한 복합 모델까지 다양한 조합을 실험한다.
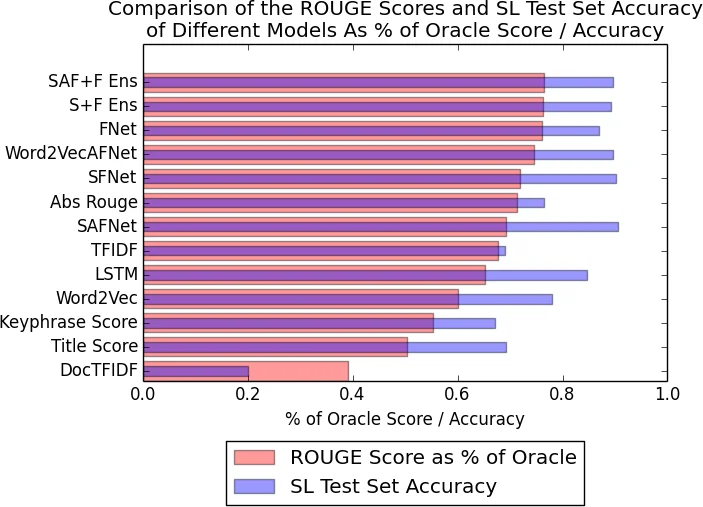
실험 결과는 두 가지 측면에서 의미가 있다. 첫째, HighlightROUGE를 통해 생성된 추가 라벨이 모델 학습에 크게 기여해, CSPubSumExt 기반 모델이 CSPubSum만을 사용한 모델보다 ROUGE‑L 점수에서 평균 34%p 상승한다. 둘째, 문장 자체의 의미를 포착하는 LSTM 인코더와 전통적인 특징을 결합한 모델(S + F Net 등)이 단순 TF‑IDF 기반 베이스라인(예: LexRank, TextRank)보다 68%p 높은 점수를 기록한다. 특히 섹션 위치와 AbstractROUGE가 가장 중요한 특징으로 확인되었으며, 이는 과학 논문에서 서론·결과·방법 등 특정 섹션이 요약에 더 기여한다는 기존 연구와 일치한다.
이 논문은 데이터 구축, 자동 라벨링, 특징 설계, 신경망 아키텍처 등 전 과정을 체계적으로 제시함으로써, 과학 논문 요약 연구에 필요한 인프라와 베이스라인을 동시에 제공한다. 향후 연구에서는 하이라이트와 초록을 동시에 활용한 멀티‑태스크 학습, 더 깊은 문맥 모델링(예: Transformer 기반) 및 도메인 간 전이 학습 등을 탐색할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기