고장에 강한 합의 알고리즘
초록
본 논문은 트랜잭션 참가자와 디스패처‑밸리데이터 관리자를 이용한 새로운 결함 허용 합의 메커니즘을 제안한다. 메시지 복제 검증, 리더(디스패처) 선출, TLA+ 기반 형식 검증을 통해 안전성을 증명하고, 5대 노드 환경에서 평균 235 ms의 응답 시간을 기록한다.
상세 분석
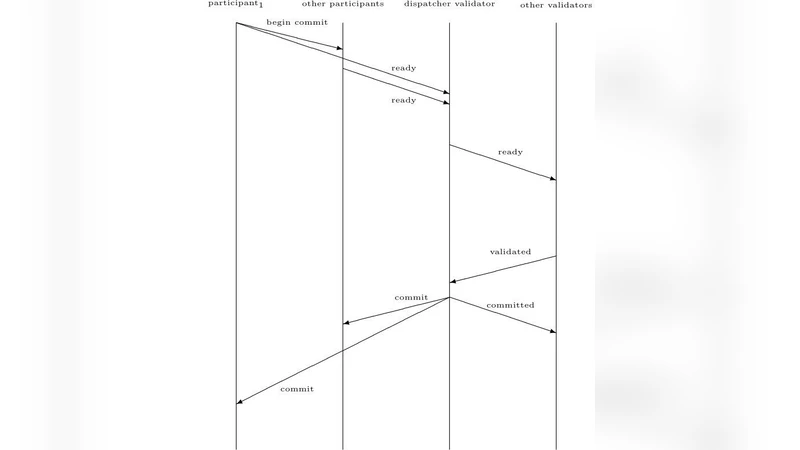
이 알고리즘은 기존 Paxos·Raft 계열의 합의 프로토콜과 달리 “디스패처‑밸리데이터”라는 특수 노드를 도입하여, 트랜잭션 매니저가 전송한 Begin 메시지 이후 각 참가자가 Ready 메시지를 디스패처에 전달하고, 디스패처가 이를 검증·전파한 뒤 다수결에 의해 Commit 혹은 Rollback을 결정한다는 흐름을 갖는다. 핵심은 디스패처가 실패하더라도 검증된 Ready 메시지를 보관하고, 새로운 디스패처가 선출될 때 모든 미처리 Ready 메시지를 재전송하도록 요구함으로써 “중단 없는 커밋”을 보장한다는 점이다.
알고리즘은 비동기 시스템을 가정하고, 메시지는 손실·중복·재정렬될 수 있으나 손상되지 않는다고 전제한다. 이러한 가정 하에 TLA+로 형식화된 사양을 제시하고, 다섯 가지 정의를 통해 (1) 투표 라운드가 단조 증가, (2) 선출 라운드에 다수의 코디네이터가 존재하지 않음, (3) 최종적으로 하나의 디스패처만 선택됨, (4) N/2‑1 이하의 밸리데이터가 다운돼도 디스패처 선출 가능, (5) 동일한 수의 밸리데이터가 다운돼도 트랜잭션 커밋이 가능함을 증명한다.
성능 평가에서는 5대 가상 머신에 분산 배치했을 때 평균 235 ms, 최소 140 ms, 최대 313 ms의 합의 지연을 기록했으며, 90 % 케이스가 289 ms 이하에서 완료되었다. 동시 1,000건 이상의 트랜잭션을 처리한 점은 확장 가능성을 시사한다.
하지만 몇 가지 한계도 존재한다. 첫째, 디스패처와 밸리데이터가 동일한 물리적 노드에 겹칠 경우 단일 장애점이 발생할 위험이 있다. 둘째, “모든 Ready 메시지를 새로운 디스패처에 재전송”이라는 복구 절차는 네트워크 폭주 시 추가 지연을 초래할 수 있다. 셋째, 논문은 TLA+ 모델 검증 결과만 제시하고 실제 코드 수준의 구현 검증이나 포괄적인 장애 시나리오(예: 네트워크 파티션, 연속적인 디스패처 교체) 실험이 부족하다. 넷째, N/2‑1 이하의 밸리데이터 장애를 허용한다는 주장은 다수결 기반이므로, 실제 운영 환경에서 복구 시간과 로그 정합성 보장이 추가적인 설계가 필요하다.
전반적으로 이 알고리즘은 기존 합의 프로토콜보다 구현이 단순하고, 디스패처 중심의 검증 흐름을 통해 장애 복구를 명시적으로 다루려는 시도가 돋보인다. 그러나 실무 적용을 위해서는 장애 복구 시 메시지 재전송 비용, 노드 역할 중복 방지, 그리고 포괄적인 실험을 통한 신뢰성 검증이 추가로 요구된다.
댓글 및 학술 토론
Loading comments...
의견 남기기