ShiftCNN 멀티플라이어 없는 저정밀 CNN 인퍼런스 아키텍처
초록
ShiftCNN는 가중치를 2의 거듭제곱 형태로 양자화해 시프트와 덧셈만으로 컨볼루션 연산을 수행한다. 가중치 코드북을 사전에 계산해 곱셈을 100배 이상 감소시키며, FPGA 구현 시 기존 8비트 고정소수점 대비 전력 소모를 4배 절감한다. 기존 모델을 재학습 없이 변환해도 정확도 손실은 1% 이하이다.
상세 분석
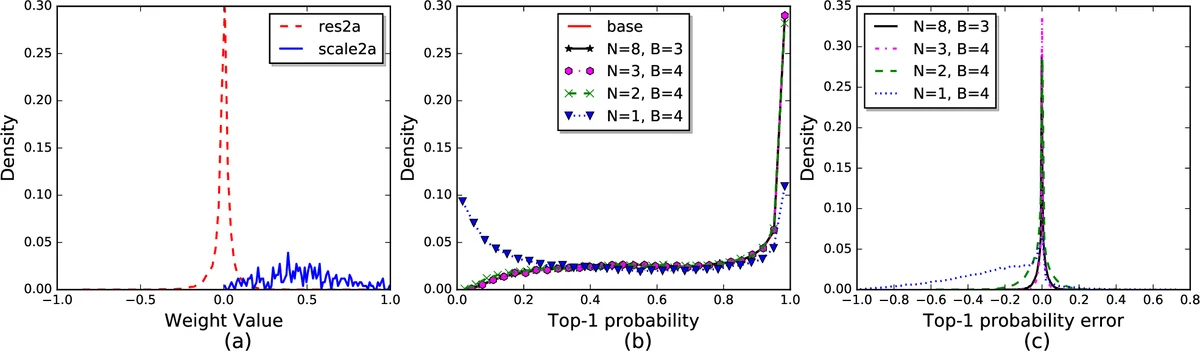
본 논문은 CNN 인퍼런스 단계에서 곱셈 연산을 완전히 없애는 ShiftCNN 아키텍처를 제안한다. 핵심 아이디어는 가중치를 2의 거듭제곱 값들의 선형 결합으로 표현하는 파워‑오브‑투(PO2) 양자화이며, 이를 위해 N개의 서브코드북 Cₙ을 정의하고 각 가중치를 B비트 인덱스로 압축한다. N=1일 경우는 이진·삼진 양자화와 동일하지만, N>1이면 보다 풍부한 표현력을 확보하면서도 하드웨어 파이프라인을 동일하게 유지할 수 있다.
양자화 과정은 알고리즘 1에 명시된 비균등 양자화 절차를 따르며, 입력 텐서를 정규화한 뒤 로그2 스케일을 이용해 가장 가까운 2⁻ᵏ 값을 선택한다. 이렇게 얻어진 코드북은 사전 계산(pre‑compute) 단계에서 입력 피처맵에 대해 모든 가능한 시프트 연산 결과를 메모리 버퍼 P에 저장한다. 이후 컨볼루션은 P에 저장된 시프트값을 인덱싱하고 단순히 덧셈을 수행함으로써 구현된다.
연산 복잡도 측면에서 기존 32비트 부동소수점 혹은 8비트 정수 CNN이 수행하던 (C_out·H_f·W_f·C_in·H·W)개의 곱셈을, ShiftCNN은 (P·C_in·H·W)개의 시프트 연산으로 대체한다. 여기서 P = M + 2(N‑1)이며, 실험에 사용된 모델들에서는 P가 (C_out·H_f·W_f)보다 크게 작아 100배 이상 연산량 감소를 달성한다. 덧셈 연산은 N배 증가하지만, 시프트 연산에 비해 전력·면적 비용이 낮아 전체적인 효율성 향상이 가능하다.
하드웨어 구현에서는 ShiftALU라는 전용 시프트·부호 반전 유닛을 설계하고, 다중 멀티플렉서와 가산 트리를 결합해 높은 병렬성을 확보한다. 메모리 버퍼는 P·C_in·H·W 크기의 2D 시프트 레지스터 배열로 구현해 대역폭 병목을 최소화한다. FPGA RTL 시뮬레이션 결과, 동일한 클럭 주파수에서 전력 소모가 기존 8비트 고정소수점 설계 대비 4배 감소했으며, 리소스 사용량도 크게 줄었다.
정량적 평가에서는 ImageNet 상의 SqueezeNet, GoogleNet, ResNet‑18/50 등 최신 모델을 N>2, B=4 설정으로 변환했을 때 Top‑1 정확도 손실이 0.010.29%에 불과했다. 특히 ResNet‑50은 72.58% (Top‑1)와 90.97% (Top‑5)의 정확도를 유지하면서 연산량을 23% 수준으로 축소했다. 이는 기존의 이진·삼진 양자화가 첫·마지막 레이어에서 고정소수점 복귀를 요구하는 것과 달리, 전 레이어를 동일한 PO2 코드북으로 처리할 수 있음을 의미한다.
종합하면 ShiftCNN은 (1) 파워‑오브‑투 가중치 양자화로 곱셈을 시프트로 대체, (2) 사전 계산 메모리와 인덱싱을 통한 연산량 감소, (3) FPGA/ASIC 친화적인 저전력·저면적 구현이라는 세 축을 동시에 만족한다. 다만 사전 계산을 위한 추가 메모리와 인덱스 관리 로직이 필요하고, N·B 조합에 따라 코드북 크기가 급증할 수 있어 메모리 제약이 있는 엣지 디바이스에서는 파라미터 선택이 중요하다. 향후 연구에서는 동적 코드북 압축, 스파스 가중치와의 결합, 그리고 배치 크기가 1인 경우에도 효율적인 파이프라인 설계가 요구된다.
댓글 및 학술 토론
Loading comments...
의견 남기기