클로즈니스 순위 추정의 혁신: 초고속 로지스틱 회귀 기반 방법
초록
본 논문은 전통적인 O(n·m) 복잡도의 클로즈니스 중심성 순위 계산을 대폭 개선하고자, 실세계 규모‑프리 네트워크에서 역순위와 클로즈니스 값 사이에 나타나는 시그모이드 형태를 로지스틱 함수로 모델링한다. 파라미터를 몇 번의 BFS와 간단한 샘플링만으로 추정함으로써 O(m) 수준의 시간복잡도로 개별 노드의 순위를 추정한다. α=3인 기본 히어리스틱과 α≈10–100인 샘플링 기반 확장 버전을 제안하고, 실제 소셜 네트워크 데이터셋에서 절대·가중 오차를 통해 정확성을 검증하였다.
상세 분석
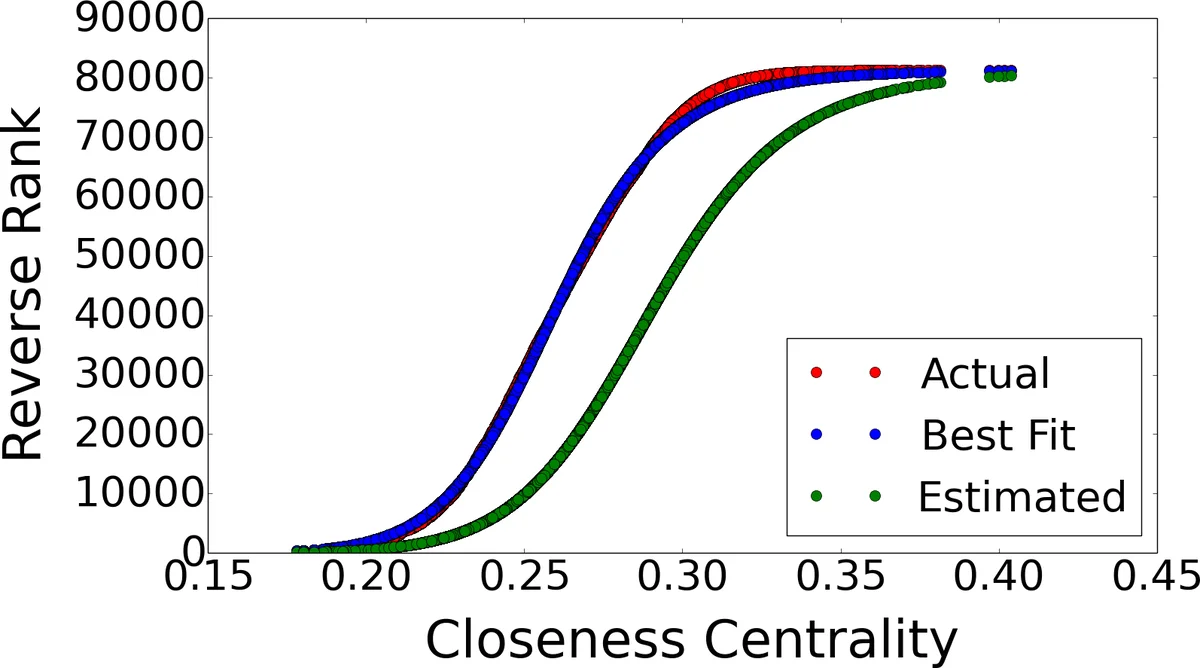
이 연구는 클로즈니스 중심성 순위 추정이라는 실용적 문제에 대한 새로운 관점을 제시한다. 기존 방법은 모든 노드에 대해 BFS를 수행해 O(n·m)이라는 비현실적인 비용을 요구했지만, 저자들은 실세계 규모‑프리 그래프에서 “중심부 → 주변부”로 갈수록 클로즈니스 값이 급격히 변하고, 역순위와의 관계가 S자형(시그모이드) 곡선을 이룬다는 경험적 사실을 발견했다. 이를 4‑parameter 로지스틱 함수 R_rev(u)=n+1−n/(1+e^{p·(C(u)−c_mid)}) 형태로 수식화하고, 두 파라미터 c_mid(중간 순위 노드의 클로즈니스)와 p(곡선의 기울기)를 추정한다. c_mid은 네트워크 전체의 최소·최대 클로즈니스를 근사한 뒤, 중앙값을 추정하는 간단한 샘플링 절차로 얻으며, p는 중앙부와 주변부의 거리 차이를 이용한 선형 회귀로 계산한다. 이렇게 파라미터를 한 번만 구하면, 임의의 노드에 대해 C(u)만 알면 O(1) 시간에 순위를 예측할 수 있다.
알고리즘 복잡도는 기본 히어리스틱에서 α=3, 즉 3번의 BFS만 수행해 O(m) 수준이며, 샘플링 기반 확장에서는 α를 10100 사이로 조정해 정확도를 높인다. 실험에서는 Brightkite, DBLP, Digg, Enron 등 10여 개의 대형 소셜 네트워크(노드 수 5만3백만, 엣지 수 2백만1천2백만)를 대상으로 절대 오차와 가중 오차를 측정했다. 결과는 평균 절대 오차가 25% 수준이며, 가중 오차는 1% 이하로, 기존 근사 방법보다 현저히 낮은 오류를 보였다.
하지만 몇 가지 한계도 존재한다. 시그모이드 가정은 주로 규모‑프리, 높은 중심성 집중도를 가진 네트워크에만 적용 가능하며, 균일한 연결성을 가진 그래프(예: 격자, 랜덤 정규 그래프)에서는 곡선 형태가 달라 파라미터 추정이 부정확할 수 있다. 또한 c_mid과 p를 추정하는 과정에서 몇 번의 BFS와 샘플링이 필요하므로, 완전한 O(1) 시간은 아니며, 파라미터 재추정이 필요할 경우 전체 비용이 증가한다. 이론적 오류 상한이나 확률적 보장은 제시되지 않아, 실험적 검증에 크게 의존한다는 점도 비판적이다.
그럼에도 불구하고, 클로즈니스 순위가 실제 응용(예: 영향력자 선정, 서비스 위치 최적화)에서 핵심 역할을 하는 상황에서, 전체 네트워크를 매번 재계산하지 않고도 빠르게 순위를 얻을 수 있다는 점은 큰 실용적 가치를 제공한다. 특히 동적 네트워크에서 파라미터를 주기적으로 업데이트하면, 실시간 순위 추정이 가능해 기존의 배치식 중앙성 계산을 대체할 잠재력이 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기