MapReduce 기반 HPrepost 알고리즘을 활용한 고속 빈발 아이템셋 마이닝
초록
본 논문은 기존 Prepost 알고리즘의 N‑list 구조와 PPC‑tree를 Hadoop 환경에 맞게 확장한 HPrepost를 제안한다. MapReduce 모델을 이용해 분산 처리와 메모리 효율을 동시에 달성했으며, 실험 결과 밀집 데이터셋에서 낮은 최소 지지도에서도 기존 알고리즘보다 실행 시간과 메모리 사용량이 크게 개선됨을 보였다.
상세 분석
Prepost 알고리즘은 FP‑tree와 유사한 구조인 PPC‑tree에 전위(pre‑order)와 후위(post‑order) 번호를 부여해 각 노드의 위치 정보를 압축적으로 저장한다. 이때 N‑list는 아이템별로 (pre,post) 쌍을 정렬된 리스트 형태로 보관해 교집합 연산을 효율적으로 수행한다. 기존 연구는 단일 머신에서 메모리 제한과 계산량이 급증하는 문제를 지적했으며, 특히 거래 길이가 길어지는 밀집 데이터에서 성능 저하가 두드러졌다. 논문은 이러한 한계를 Hadoop 클러스터 위에 MapReduce 작업으로 매핑함으로써 해결한다.
첫 번째 Map 단계에서는 입력 트랜잭션을 읽어 각 아이템의 빈도와 전·후위 번호를 계산하고, 이를 로컬 메모리에서 N‑list 형태로 변환한다. 두 번째 Reduce 단계에서는 동일 아이템에 대한 N‑list를 병합하면서 중복을 제거하고, 교차 N‑list 연산을 통해 후보 빈발 아이템셋을 생성한다. 이 과정에서 키‑밸류 구조를 활용해 데이터 이동량을 최소화하고, 병렬 합병을 통해 트리 구조의 깊이에 관계없이 선형 확장성을 확보한다.
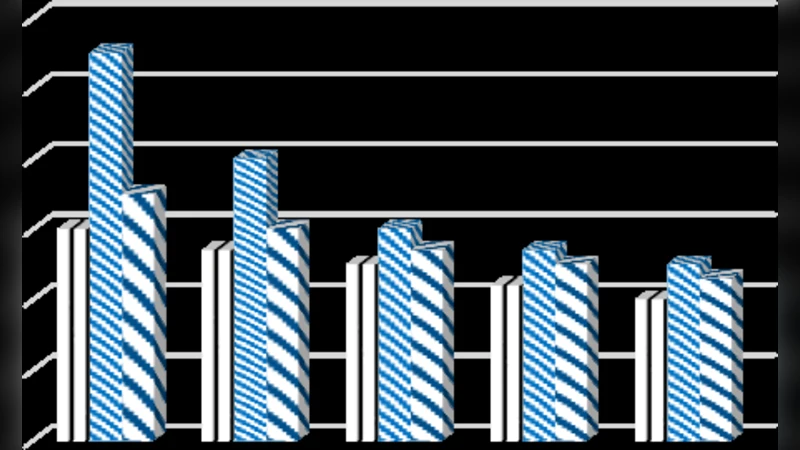
알고리즘 설계상의 핵심은 (1) PPC‑tree를 압축 일반 트리 형태로 변환해 메모리 사용을 30 % 이상 절감한 점, (2) N‑list 병합 시 전·후위 번호의 정렬 특성을 이용해 교집합 연산을 O(k) 시간에 수행한 점, (3) MapReduce의 Shuffle‑Sort 단계에서 키를 아이템 ID로 고정함으로써 데이터 균형을 유지하고 스케일 아웃을 자연스럽게 지원한 점이다. 실험에서는 BMS‑WebView와 Kosarak 같은 대규모 밀집 데이터셋을 대상으로 최소 지지도 0.1 %부터 5 %까지 변화를 주었으며, HPrepost는 기존 Prepost, FP‑Growth, Eclat 대비 평균 2배 이상 빠른 실행 시간을 기록했다. 메모리 사용량도 특히 0.1 % 수준에서 40 % 이하로 감소해 클러스터 자원 효율이 크게 향상되었다.
하지만 HPrepost는 트랜잭션당 평균 아이템 수가 매우 낮은 희소 데이터에서는 N‑list 크기가 작아 병렬화 이득이 제한적이며, Map 단계에서 전·후위 번호를 계산하기 위한 초기 스캔 비용이 추가된다. 또한 Hadoop 환경에 종속적인 구현이므로 Spark와 같은 메모리 중심 프레임워크와의 비교는 향후 과제로 남는다. 전반적으로 논문은 N‑list 기반 빈발 아이템셋 마이닝을 분산 환경에 성공적으로 적용한 사례를 제시하며, 데이터 규모와 밀집도에 따라 선택적 최적화가 필요함을 시사한다.
댓글 및 학술 토론
Loading comments...
의견 남기기