레시듀얼 네트워크의 비밀: 왜 “2‑shortcut”이 최적일까
본 논문은 ResNet에서 사용되는 shortcut 연결의 깊이(길이)가 학습 난이도에 미치는 영향을 이론적으로 분석한다. 길이가 2인 shortcut은 Hessian의 조건수가 깊이에 무관하게 유지되어 최적화가 쉬운 반면, 길이 1은 조건수가 무한대로 발산하고, 길이 ≥ 3은 고차원 고정점(극히 평탄한 지점)으로 인해 탈출이 어렵다. 제로 초기화와 작은 무작위 교란을 이용한 실험이 이론을 뒷받침한다.
저자: Sihan Li, Jiantao Jiao, Yanjun Han
본 논문은 2015년 He 등(ResNet)에서 제안된 shortcut 연결이 왜 깊은 신경망의 학습을 크게 용이하게 하는지를 수학적으로 규명한다. 기존 연구에서는 residual block이 “identity mapping”을 학습하도록 돕는 직관적 설명이 주를 이뤘지만, 정확히 어떤 구조적 특성이 조건수를 안정화시키는지는 밝혀지지 않았다. 저자들은 이를 해결하기 위해 다음과 같은 단계적 접근을 취한다.
1. **모델 정의**
- 선형 residual unit을 기본으로 하여, 각 unit이 L개의 레이어와 깊이 n인 shortcut(항등 행렬)으로 구성된 n‑shortcut 선형 네트워크를 정의한다.
- 비선형 활성화 함수(σ_pre, σ_mid, σ_post)를 변환 경로에 삽입해 일반적인 n‑shortcut 네트워크로 확장한다. 활성화 함수는 0에서 0을 출력하고, 필요한 차수까지 미분 가능하다는 최소 가정만 둔다.
2. **Zero 초기화와 작은 교란**
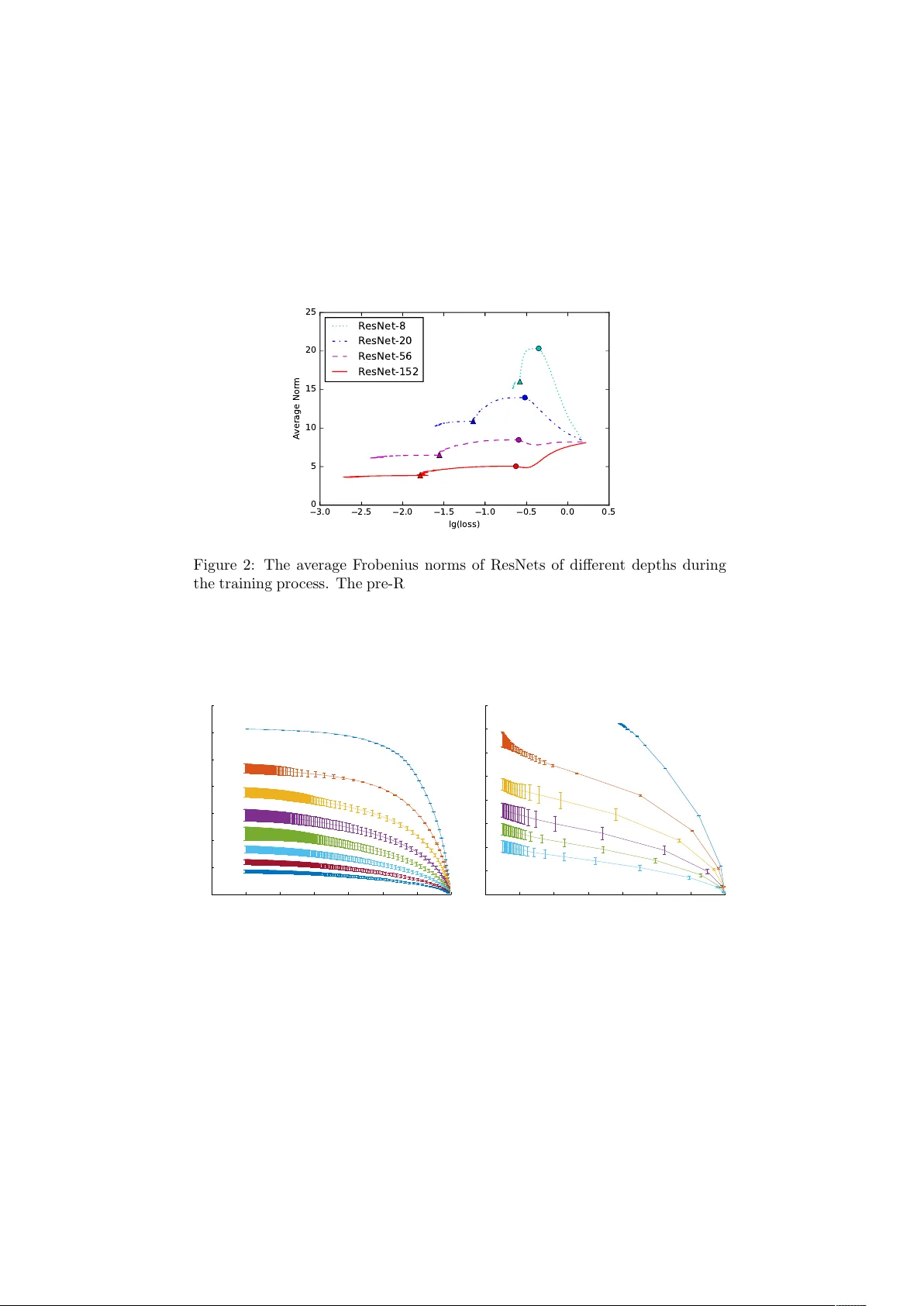
- ResNet에서 흔히 쓰이는 MSRA(He) 초기화는 깊어질수록 출력 분산이 폭발한다는 문제를 지적하고, 모든 가중치를 0으로 초기화한 뒤 작은 랜덤 교란(σ=0.01)으로 탈출하는 방식을 제안한다. 이는 실험적으로도 평균 가중치 노름이 깊어질수록 감소함을 보여준다(그림 2, 3).
3. **Theorem 1 – Small‑Weight Global Minimum**
- 입력 데이터가 정규화되고 최소 거리 ρ를 만족한다는 가정 하에, 깊이 R인 2‑shortcut 네트워크가 존재함을 증명한다. 특히 각 가중치 행렬의 Frobenius norm이 \(\mathcal{O}(r^{-1/n})\) 이하로 감소한다는 결과는, 깊어질수록 최적 해가 0에 가까워짐을 의미한다. 이는 “zero‑init”이 실제 학습 과정에서 좋은 시작점이 될 수 있음을 이론적으로 뒷받침한다.
4. **Theorem 2 – Hessian 구조와 조건수**
- 손실 함수의 0점에서의 고차 정적점 특성을 분석한다.
- n ≥ 3: Hessian이 영행렬이므로 (n‑1)차 고정점이며, 1차 최적화가 거의 불가능한 평탄 지대에 머문다.
- n = 2: Hessian은 블록 대각 형태 \(H=\begin{bmatrix}0&A^{\top}\\A&0\end{bmatrix}\) 로 나타나며, 조건수는 \(\operatorname{cond}(H)=q\,\operatorname{cond}(A^{\top}A)\) 로 깊이에 독립적이다. 따라서 2‑shortcut 네트워크는 레이어 수가 늘어나도 최적화 난이도가 일정하게 유지된다.
- n = 1: Hessian은 Toeplitz‑like 구조를 가지며, 조건수가 레이어 수에 비례해 급격히 증가한다. 이는 기존 “plain” 네트워크와 동일한 어려움을 나타낸다.
5. **실험**
- **초기 조건수 측정**: 선형 네트워크에 대해 2‑shortcut, Orthogonal, Xavier 초기화를 각각 10번씩 실행해 조건수를 측정한다. 2‑shortcut은 깊이가 2000층까지도 조건수가 거의 변하지 않지만, 다른 두 초기화는 깊이가 증가함에 따라 무한대로 발산한다(그림 4).
- **학습 동역학**: 동일한 설정에서 2‑shortcut zero‑init, 1‑shortcut Orthogonal, 그리고 Xavier 초기화를 비교한다. 2‑shortcut은 손실 감소 속도가 빠르고, 최종 손실이 가장 낮으며, Hessian eigenvalue 분포도 안정적이다. 반면 1‑shortcut은 학습 초기에 급격히 발산하거나 정체되는 현상이 관찰된다.
- **가중치 노름**: 깊은 네트워크일수록 평균 가중치 노름이 작아지는 현상이 확인된다. 이는 Theorem 1에서 예측한 “가중치가 0에 수렴”하는 경향과 일치한다.
6. **논의 및 결론**
- 2‑shortcut이 특별히 좋은 이유는 두 가지이다. 첫째, Hessian의 조건수가 깊이에 무관해 최적화가 안정적이다. 둘째, 0점이 (n‑1)차 고정점이 아닌 2차 고정점이므로, 첫 번째 미분(gradient)만으로도 충분히 탈출할 수 있다.
- 1‑shortcut은 사실상 shortcut이 없는 경우와 동일하게 조건수가 폭발해 깊은 네트워크에서 학습이 어려워진다.
- 3‑이상 shortcut은 고차 고정점(조건수 0)으로 인해 최적화가 거의 불가능해진다.
- 따라서 ResNet 설계 시 “2‑layer shortcut”이 이론적으로도 최적임을 입증했으며, zero‑initialization과 작은 교란을 결합한 초기화 전략이 기존 Xavier·Orthogonal보다 우수함을 실험적으로 확인했다.
이러한 결과는 ResNet의 성공을 단순히 “identity mapping”이라는 직관이 아니라, 고차 미분 구조와 조건수 관점에서 이해할 수 있음을 보여준다. 향후 연구에서는 비선형 활성화 함수의 구체적 형태가 Hessian 구조에 미치는 영향, 그리고 배치 정규화와 같은 추가 기법이 이론적 분석에 어떻게 통합될 수 있는지를 탐구할 여지가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기