운전 패턴 기반 자동차 궤적 라벨링 프레임워크와 DACT 데이터셋
초록
본 논문은 개인 차량 궤적을 운전 패턴별로 구분·라벨링하기 위한 크라우드소싱 기반 어노테이션 프레임워크를 제안하고, 전문가와 집계 단계의 두 단계로 구성된 절차를 상세히 기술한다. 최종적으로 5천여 개의 라벨링된 궤적을 포함한 DACT 데이터셋을 공개한다.
상세 분석
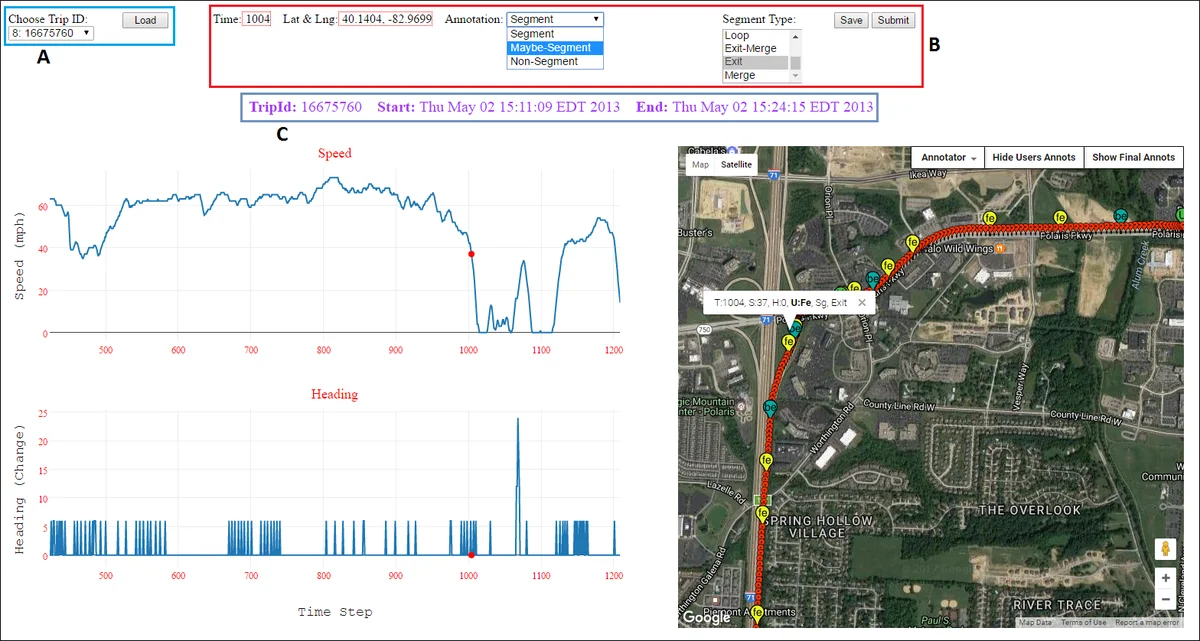
이 연구는 차량 궤적 분석 분야에서 가장 근본적인 문제인 ‘정답 라벨(ground‑truth) 부재’를 해결하고자 한다. 저자들은 먼저 궤적을 시간‑스탬프와 속도·방위·위치 등 다중 속성으로 정의하고, 이를 ‘세그먼트(패턴)’와 ‘세그먼트 경계(컷 포인트)’로 구분한다. 핵심 기여는 두 단계의 어노테이션 파이프라인이다. ① 전문가 어노테이션 단계에서는 웹 기반 포털을 구축해 속도 프로파일, 헤딩 변화, 지도 상 위치를 동시 시각화한다. 사용자는 각 포인트를 ‘Segment’, ‘Maybe‑Segment’, ‘Non‑Segment’ 중 하나로 지정하고, 패턴 종류(가속, 감속, 회전, 합류 등)를 선택한다. 포털은 Plot.ly와 Google Maps API를 활용해 연동된 뷰를 제공함으로써 인간 인지 부하를 최소화한다. ② 집계 단계에서는 동일 궤적에 대해 두 명 이상의 어노테이터가 제공한 라벨을 통합한다. 저자들은 ‘Strict Aggregation’과 ‘Easy Aggregation’이라는 두 가지 기준을 도입한다. Strict 단계에서는 최소 5 mph 속도 변화 혹은 5초 연속 헤딩 변화와 같은 엄격한 임계값을 적용해 모든 가능한 세그먼트를 포착하고, ‘Segment’와 ‘Maybe‑Segment’를 구분한다. Easy 단계에서는 보다 관대하게 라벨을 합치며, 전문가가 직접 ‘Accept’, ‘Refine’, ‘Reject’를 선택한다. 또한, 자동화된 휴리스틱 라벨을 보조 입력으로 활용해 인간 라벨과의 일관성을 검증한다.
데이터셋 구축 과정에서도 중요한 설계 선택이 눈에 띈다. 저자들은 4명의 대학생, 2명의 연구원, 1명의 보험 전문가 등 다양한 배경을 가진 어노테이터를 모집했으며, 파일럿 테스트를 통해 작업 흐름을 최적화했다. 각 궤적은 최소 두 명에게 할당되어 중복 라벨링을 보장했고, 이를 통해 라벨 간 신뢰도(Inter‑Annotator Agreement)를 정량화할 수 있는 기반을 마련했다.
기술적 한계도 명시한다. 라벨링은 본질적으로 주관적이며, ‘Maybe‑Segment’와 같은 불확실성 표시는 데이터 활용 시 추가적인 전처리 혹은 불확실성 모델링이 필요함을 암시한다. 또한, 현재는 미국 중서부 지역의 개인 차량 데이터에 국한돼 있어, 다른 지역·문화·도로 환경에 대한 일반화 가능성은 검증되지 않았다.
이 논문의 가장 큰 의의는 공개된 DACT 데이터셋이다. 기존의 뉴욕 택시, 포르투 택시, GeoLife 등은 차량 움직임 자체만을 제공했지만, DACT는 인간 전문가가 정의한 운전 패턴 라벨을 포함한다. 이는 향후 세그먼트 기반 운전 행동 분석, 위험도 예측, 보험 청구 자동화 등 다양한 응용 연구에 표준 벤치마크로 활용될 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기