커뮤니티 질문답변 연구 조사
초록
본 논문은 커뮤니티 기반 질문답변(cQA) 시스템에서 직면하는 주요 과제인 질문 중복 탐지와 답변 선택 문제를 중심으로 기존 연구들을 정리한다. 전통적인 QA와 cQA의 차이를 설명하고, BM25, TransLM, 워드 임베딩, 신경망 기반 어텐션 모델 등 다양한 방법론을 비교한다. 또한 TREC QA, Yahoo! Answers, Quora 데이터셋을 활용한 실험 결과를 제시하며, 토큰 매칭 방식의 한계와 딥러닝 모델의 우수성을 논의한다.
상세 분석
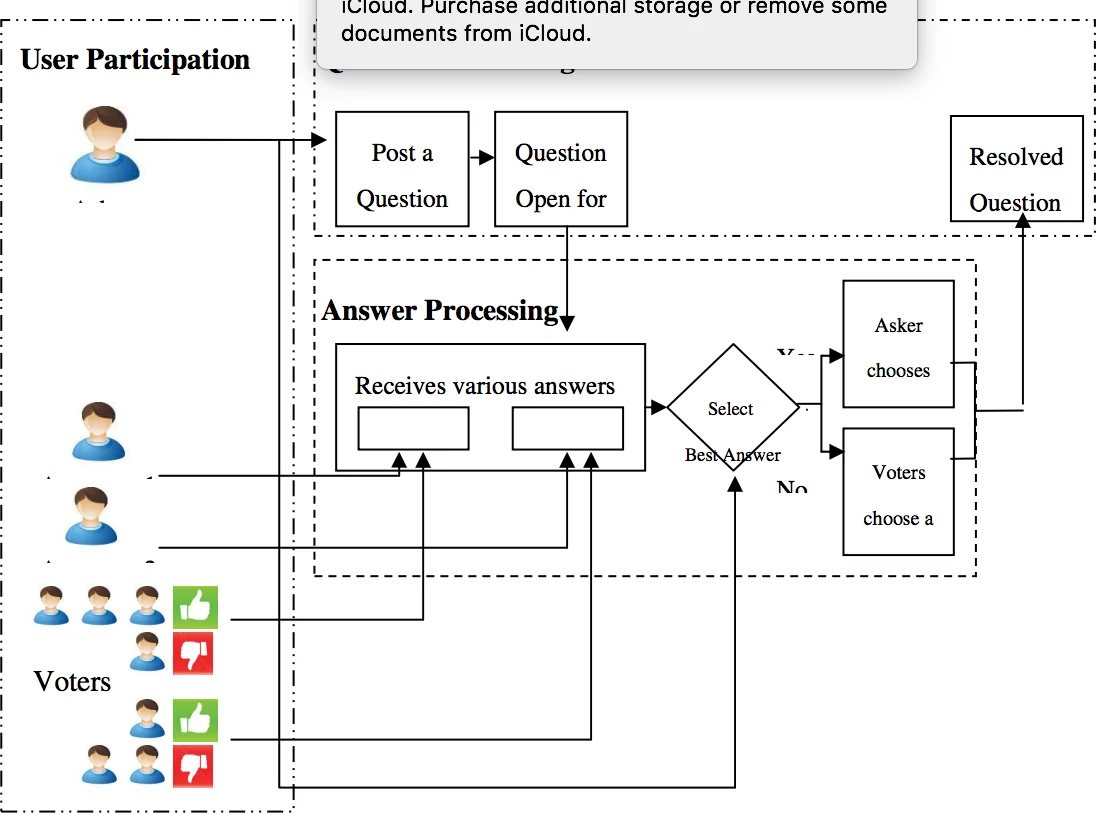
이 논문은 커뮤니티 질문답변(cQA) 영역을 전통적인 질문답변(QA)과 구분함으로써 연구의 출발점을 명확히 한다. 전통 QA가 짧고 명확한 사실형 질문에 초점을 맞추는 반면, cQA는 다중문장으로 구성된 복합 질문과 사용자 생성 답변을 다루며, 메타데이터(업보트, 답변자 평점 등)를 활용할 수 있다는 점을 강조한다. 주요 과제로는 (1) 질문 의미 매칭, 즉 중복 질문 탐지와 (2) 질문‑답변 매칭, 즉 최적 답변 선택이 제시된다.
첫 번째 과제인 질문 의미 매칭에서는 초기 방법으로 Okapi BM25와 TransLM이 소개된다. BM25는 토큰 기반 가중치 매칭을 이용해 비대칭 점수를 평균해 대칭 점수를 산출한다. TransLM은 질문을 번역 모델로 간주해 P(q₁|q₂)와 P(q₂|q₁)를 평균함으로써 어휘 격차를 완화한다. 그러나 두 방법 모두 단어 수준의 겹침에 크게 의존하므로 어휘 다양성이 큰 cQA에서는 성능이 제한적이다.
이를 보완하기 위해 워드 임베딩 기반 방법과 신경망 어텐션 모델이 도입된다. 워드 임베딩은 질문을 실수 벡터로 변환하고, 다층 퍼셉트론(MLP)이나 LSTM을 통해 문장 수준 표현을 학습한다. Parikh et al.(2016)의 토큰 정렬 어텐션은 두 질문 간의 상호주의적 어텐션 행렬을 구축하고, 이를 통해 각 토큰의 중요도를 동적으로 조정한다. 이러한 구조는 의미적 유사성을 보다 정교하게 포착한다.
두 번째 과제인 질문‑답변 매칭에서도 유사한 흐름이 관찰된다. BM25와 TransLM을 그대로 적용하면 질문과 답변 사이의 토큰 겹침이 적어 낮은 점수를 받는다. 따라서 CNN 기반 임베딩, Bi‑LSTM + CNN, 그리고 어텐션을 결합한 하이브리드 모델이 제안된다. 특히 Qiu와 Huang(2015)의 Deep CNN은 다중 k‑max 풀링과 텐서 상호작용을 활용해 질문·답변 벡터 간의 복합적 관계를 모델링한다. 손실 함수는 마진 기반 혹은 로그우도 기반으로 설계되어, 정답과 오답을 효과적으로 구분한다.
실험에서는 TREC QA(사실형 질문), Yahoo! Answers(대규모 실사용 데이터), Quora(질문‑질문 유사도) 세 가지 데이터셋을 사용한다. 평가 지표는 MAP, MRR, P@1, P@10 등이다. 결과표를 보면 전통적인 BM25와 TransLM은 30~40% 수준의 P@1을 기록하는 반면, 워드 임베딩 + CNN, CNTN, QA‑LSTM with Attention 등 딥러닝 기반 모델은 70% 이상, 심지어 82%에 달하는 P@1을 달성한다. 이는 어휘 격차를 극복하고 문맥 정보를 효과적으로 활용한 것이 주요 원인으로 해석된다.
논문의 토론 부분은 이러한 실험 결과를 바탕으로 토큰 매칭 방식의 근본적인 한계를 지적한다. cQA에서는 질문과 답변이 서로 다른 어휘 집합을 사용하면서도 의미적으로 연결될 가능성이 높으며, 따라서 의미적 매핑을 위한 고차원 임베딩과 어텐션 메커니즘이 필수적이다. 또한 메타데이터(업보트, 답변자 평점 등)를 활용한 다중 모달 접근법이 향후 연구 방향으로 제시된다. 전체적으로 이 논문은 cQA 연구의 흐름을 체계적으로 정리하고, 최신 딥러닝 기술이 전통 모델을 대체할 수 있음을 실증적으로 보여준다.
댓글 및 학술 토론
Loading comments...
의견 남기기