압축 DMA 엔진으로 활성값 희소성 활용한 딥러닝 메모리 가상화
초록
본 논문은 GPU 메모리 한계를 극복하기 위해 활성값(activation) 맵의 높은 희소성을 이용해 데이터를 압축하고, 압축된 데이터를 PCIe를 통해 CPU 메모리와 교환하는 압축 DMA 엔진(cDMA)을 제안한다. 평균 2.6배(최대 13.8배)의 압축률을 달성해 기존 vDNN 방식 대비 평균 32%(최대 61%)의 성능 향상을 보인다.
상세 분석
이 연구는 GPU 메모리 용량이 제한적인 상황에서 DNN 학습을 지속 가능하게 만들기 위한 메모리 가상화 기법인 vDNN의 한계를 정확히 짚어낸다. vDNN은 활성값 맵을 CPU 메모리로 오프로드하고 필요 시 다시 프리패치함으로써 GPU 메모리 사용량을 크게 줄이지만, PCIe 대역폭(16 GB/s)과 GPU DRAM 대역폭(336 GB/s)의 격차 때문에 데이터 전송이 병목이 된다. 특히 최신 cuDNN이 연산 속도를 크게 끌어올리면서 전송‑연산 겹치 시간이 감소해 성능 손실이 30% 이상으로 악화되는 현상이 관찰된다.
논문은 이러한 문제를 해결하기 위해 활성값 맵이 ReLU 비선형성에 의해 대량의 0값을 포함한다는 사실에 주목한다. 실험적으로 AlexNet, VGG, GoogLeNet 등 여러 CNN 모델에서 레이어별 평균 활성값 밀도가 10%~30% 수준으로 낮으며, 훈련 진행 중에도 높은 희소성이 유지됨을 보여준다. 이러한 희소성을 기반으로 압축 알고리즘을 적용하면 데이터 크기가 크게 감소한다.
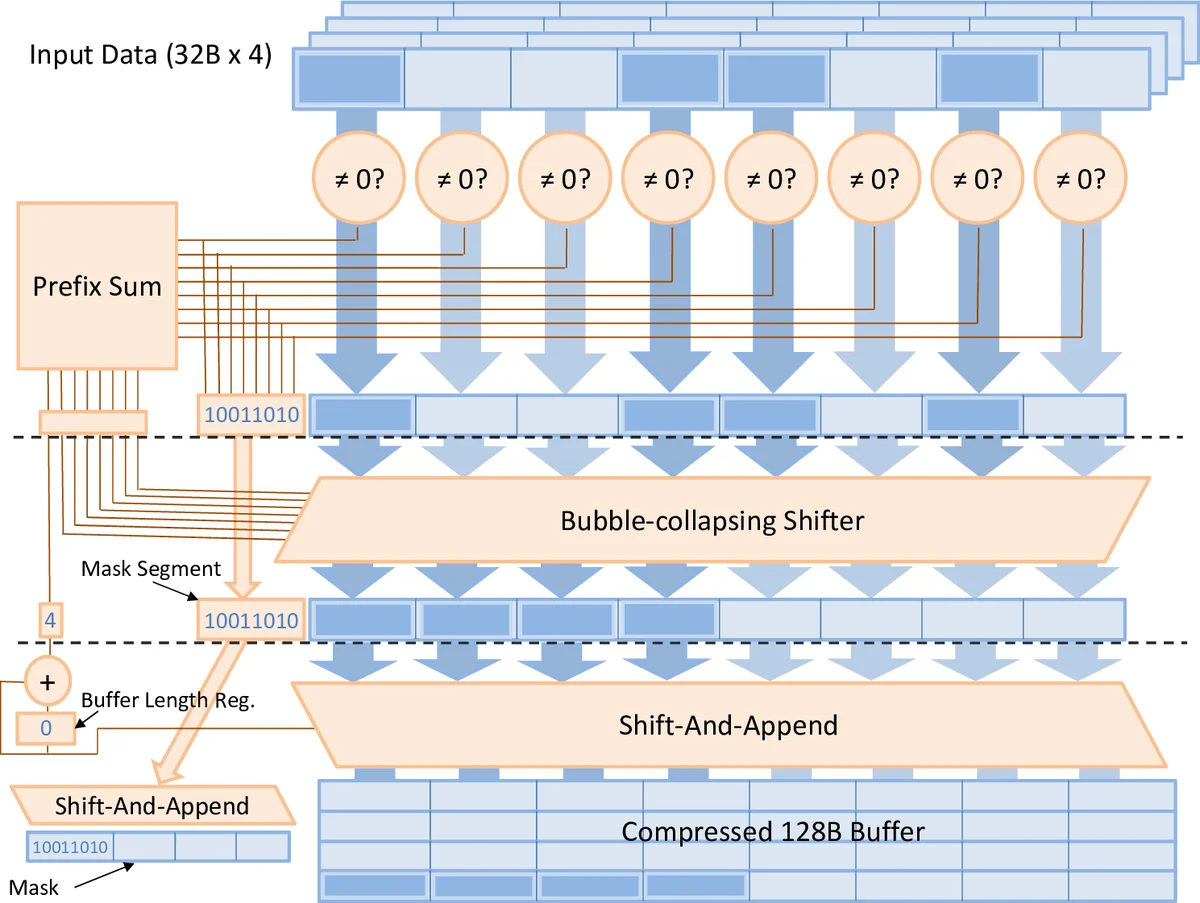
cDMA는 기존 GPU 메모리 컨트롤러에 내장된 압축/복원 유닛을 재활용해 설계 복잡도를 최소화한다. 데이터가 GPU 메모리에서 읽혀질 때, 압축 엔진이 실시간으로 0값을 제거하고 비트‑레벨 압축을 수행한다. 압축된 스트림은 PCIe를 통해 CPU 메모리로 전송되고, 필요 시 GPU로 복원된다. 핵심 설계 포인트는 (1) 압축률에 따라 실질적인 전송 대역폭을 압축 × PCIe 대역폭 수준으로 맞추어 전송 지연을 최소화하고, (2) 압축/복원 연산이 메모리 컨트롤러 수준에서 파이프라인화돼 GPU 연산 파이프라인을 방해하지 않도록 하는 것이다.
성능 평가에서는 cDMA가 평균 2.6배(최대 13.8배)의 압축률을 달성했으며, 이는 vDNN 대비 평균 32%(최대 61%)의 실행 시간 감소로 이어졌다. 특히 메모리 사용량이 GPU 한도를 크게 초과하는 대형 모델에서 압축 효과가 두드러졌다. 반면, LSTM·GRU와 같이 sigmoid·tanh 활성함수를 사용하는 RNN에는 희소성이 낮아 적용 효율이 떨어진다.
이 논문은 활성값 희소성을 활용한 하드웨어‑소프트웨어 공동 설계가 메모리 가상화 성능을 크게 개선할 수 있음을 증명한다. 향후 PCIe 5.0·NVLink와 같은 고대역폭 인터커넥트와 결합하면 압축 오버헤드가 더욱 감소해, 메모리 제한 없이 더 깊고 넓은 네트워크를 학습할 수 있는 기반이 될 것이다.
댓글 및 학술 토론
Loading comments...
의견 남기기