교사 모델이 가르치는 제로 리소스 신경망 번역 기술
초록
본 논문은 병렬 코퍼스가 없는 언어 쌍(제로 리소스)을 위한 신경망 기계 번역(NMT) 방법을 제안한다. 핵심 아이디어는 ‘번역된 문장들은 제3의 언어에서 문장을 생성할 확률이 비슷하다’는 가정이다. 이를 바탕으로, 기존에 학습된 피벗-타겟 번역 모델(교사)이 소스-피벗 병렬 코퍼스 상에서 새로운 소스-타겟 모델(학생)의 학습을 지도한다. 실험 결과, 제안된 방법은 기존 피벗 기반 모델보다 다양한 언어 쌍에서 BLEU 점수를 평균 3.0점 향상시켰다.
상세 분석
이 논문이 제안하는 ‘교사-학생(Teacher-Student)’ 프레임워크의 기술적 핵심은 ‘번역 동등성 가정(Translation Equivalence Assumption)‘에 기반한 지도 학습이다. 기존 피벗 기반 방식이 소스→피벗, 피벗→타겟의 2단계 추론을 통해 오류 전파 문제를 야기한 반면, 본 방법은 최종 목표인 소스→타겟 모델을 직접 학습시켜 단일 단계 추론을 가능하게 한다.
학습의 구동력은 피벗 문장 z에 대해 이미 학습된 ‘교사 모델’ P(y|z)이 생성하는 타겟 문장 y에 대한 확률 분포다. 이 분포를 ‘학생 모델’ P(y|x)가 소스 문장 x에 대해 모방하도록 하는 것이 목표이다. 학습은 크게 두 가지 수준에서 이루어진다:
- 문장 수준 학습: 전체 타겟 문장 y에 대한 두 모델의 확률 분포 간 KL 발산을 최소화한다(J_SENT). 이는 “소스 x가 피벗 z의 번역일 때, x와 z가 생성하는 타겟 문장 y의 전체 확률 분포가 유사해야 한다"는 가정(Assumption 1)을 반영한다.
- 단어 수준 학습: 생성 과정 중 각 단계에서 다음 타겟 단어에 대한 두 모델의 확률 분포 간 KL 발산을 누적하여 최소화한다(J_WORD). 이는 “부분 번역이 주어졌을 때, 다음 단어를 생성하는 확률도 유사해야 한다"는 보다 세부적인 가정(Assumption 2)을 구현한다.
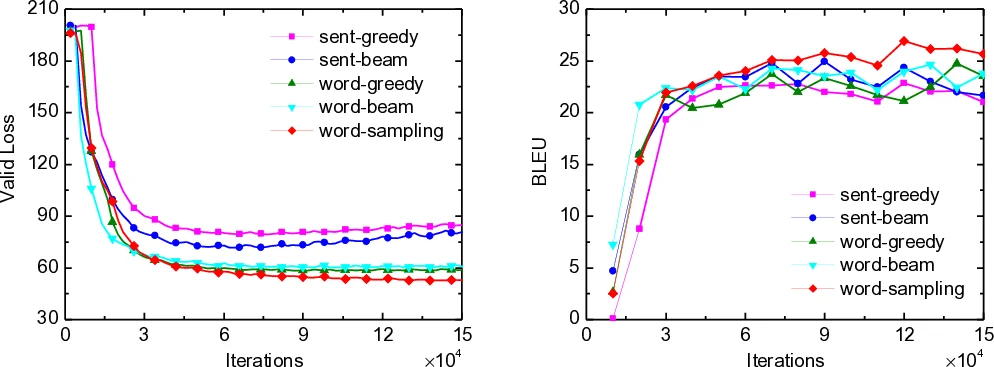
실제 구현의 핵심 과제는 타겟 문장 공간이 지수적으로 크다는 점이다. 논문은 이를 해결하기 위해 ‘모드 근사(Mode Approximation)’ 방식을 채택했다. 즉, 교사 모델로 피벗 문장 z에 대한 빔 서치를 수행하여 가장 높은 점수의 타겟 문장(모드)을 하나의 대표 샘플로 사용하여 기대값을 근사한다. 이는 샘플링 기반 방법보다 낮은 분산을 유지하면서 계산 효율성을 확보한 전략이다. 실험에서 ‘문장-빔(sent-beam)‘과 ‘단어-빔(word-beam)’ 방식이 가장 좋은 성능을 보였으며, 단어 수준 학습이 일반적으로 더 나은 결과를 제시했다. 이는 단어별 확률 분포 정렬이 모델 학습에 더 효과적인 정규화 역할을 함을 시사한다.
댓글 및 학술 토론
Loading comments...
의견 남기기