서비스 기반 검색 향상 시스템 공동어 분석과 브래드포드화 및 저자 중심성
초록
이 논문은 검색 질의를 공동어 분석으로 자동 확장하고, 결과 집합을 저널 핵심성(Bradfordizing)과 저자 네트워크 중심성(Author Centrality)으로 재정렬하는 세 가지 서비스‑드리븐 모델을 구현한 시연 시스템을 소개한다. Solr, Grails, Mindserver를 결합해 다중 학술 데이터베이스에 적용했으며, 사용자는 인터랙티브하게 서비스를 조합해 검색 결과를 점진적으로 개선할 수 있다.
상세 분석
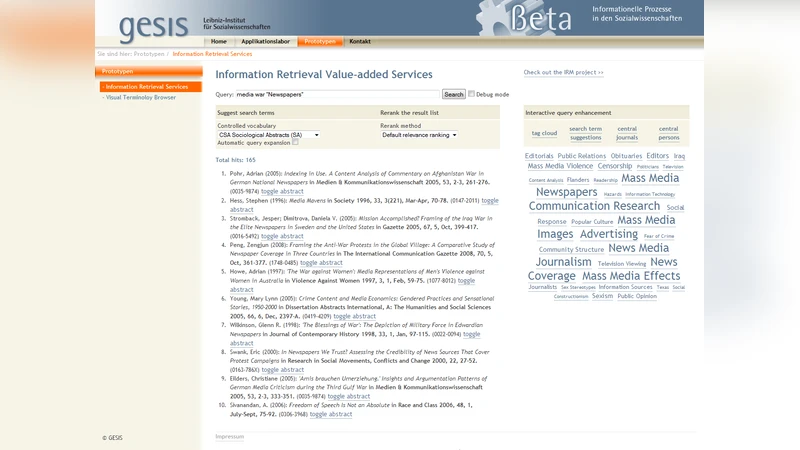
본 연구는 전통적인 TF‑IDF 기반 순위에 의존하는 검색 시스템의 한계를 보완하기 위해 세 가지 모델‑구동 서비스를 설계·구현하였다. 첫 번째 서비스는 통계적 공동어 분석에 기반한 Search Term Recommender(STR)이다. SVM과 PLSA를 활용해 문서 메타데이터(제목·초록)와 제어 어휘(전문 용어 사전) 사이의 연관성을 학습하고, 사용자가 입력한 질의에 대해 관련도가 높은 확장어를 자동으로 제시한다. 이는 ‘언어 문제’를 완화하고, 사용자가 전문 용어를 정확히 알지 못해도 적절한 검색 결과를 얻을 수 있게 한다.
두 번째 서비스인 Bradfordizing은 결과 집합 내 저널의 출현 빈도를 이용해 핵심 저널을 식별하고, 해당 저널에 속한 문서를 우선 순위에 올린다. 구현은 Solr의 facet 기능을 활용해 ISSN 기반으로 저널별 문서 수를 집계하고, 이 빈도값을 기존 점수에 가중치로 곱해 재정렬한다. 이 과정은 메타데이터(ISSN)의 존재 여부에 크게 의존하지만, 저널 중심의 학술 검색에서 과도한 결과량을 효과적으로 축소한다.
세 번째 서비스인 Author Centrality는 공동 저자 네트워크를 구축하고, 각 저자의 betweenness centrality를 계산한다. 결과 집합에 포함된 논문의 저자를 네트워크 노드로 보고, 저자 간 공동 저작 관계를 엣지로 설정한다. 중심성이 높은 저자의 논문은 검색 결과 상위에 배치되며, 이는 저자 평판·연결성에 기반한 의미적 관련성을 반영한다. 텍스트 기반 순위와는 달리 구조적 사회적 정보를 활용한다는 점이 특징이다.
시스템 아키텍처는 오픈소스 Solr을 검색 엔진으로, Grails를 웹 프레임워크로, Mindserver를 텍스트 분류·용어 추출 엔진으로 결합하였다. 이렇게 모듈화된 설계는 각 서비스의 독립적 개발·배포를 가능하게 하고, 사용자는 웹 인터페이스에서 질의 확장, Bradfordizing, 저자 중심성 재정렬을 탭 형태로 선택하거나 자동 파이프라인으로 연계할 수 있다. 데이터는 사회과학·스포츠과학·교육학 분야의 6개 데이터베이스(총 약 1.6백만 레코드)에서 메타데이터를 수집했으며, 언어(독일어·영어)와 스키마 차이를 메타데이터 정규화와 다중 어휘 매핑으로 해결하였다.
실증적 평가는 아직 논문에 포함되지 않았지만, 서비스별로 서로 다른 ‘관점’의 문서를 제공함으로써 사용자는 동일 질의에 대해 다양한 관련 문서를 탐색하고, 반복적인 인터랙션을 통해 최적의 결과에 도달할 수 있다는 점을 강조한다. 또한, 온라인 시연을 위해 지속적인 인터넷 연결과 표준 웹 브라우저(특히 Firefox)만 있으면 충분하다는 실용적 요구사항을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기