트위터 주제 분류를 위한 원거리 감독 기법
초록
본 논문은 뉴스 매체 등에서 운영하는 주제에 특화된 트위터 계정을 활용해 자동으로 라벨을 생성하고, 이를 기반으로 로지스틱 회귀와 나이브 베이즈 모델을 학습시켜 일반 및 혼합형 계정의 트윗을 실시간으로 주제별로 분류하는 방법을 제안한다. 실험 결과, 라벨이 노이즈가 있더라도 충분한 양과 최신성을 갖춘 학습 데이터가 높은 F1 점수를 달성함을 보였으며, 최근 데이터에 가중치를 부여하면 주제 드리프트에 대한 적응력이 향상된다.
상세 분석
이 연구는 기존 트위터 이벤트 탐지 방식이 대량의 비필터링된 스트림을 대상으로 잡음과 조작에 취약한 점을 지적하고, 대신 인간이 직접 큐레이션한 뉴스 계정들을 ‘자연적인 라벨링 소스’로 활용한다는 새로운 관점을 제시한다. 저자들은 293개의 미디어 계정을 수집하고, 이를 ‘focused(특정 주제에 집중)’, ‘hybrid(몇 개 주제 혼합)’, ‘general(다양한 주제)’ 세 유형으로 분류하였다. 특히 focused 계정에서 추출한 트윗을 긍정 샘플로, 다른 계정에서 무작위로 추출한 트윗을 부정 샘플로 사용해 각 주제별 이진 분류기를 구축하였다. 특징 추출은 NLTK 트위터 토크나이저를 이용한 TF‑IDF이며, 학습 모델은 scikit‑learn의 로지스틱 회귀와 다중 클래스 나이브 베이즈를 적용했다.
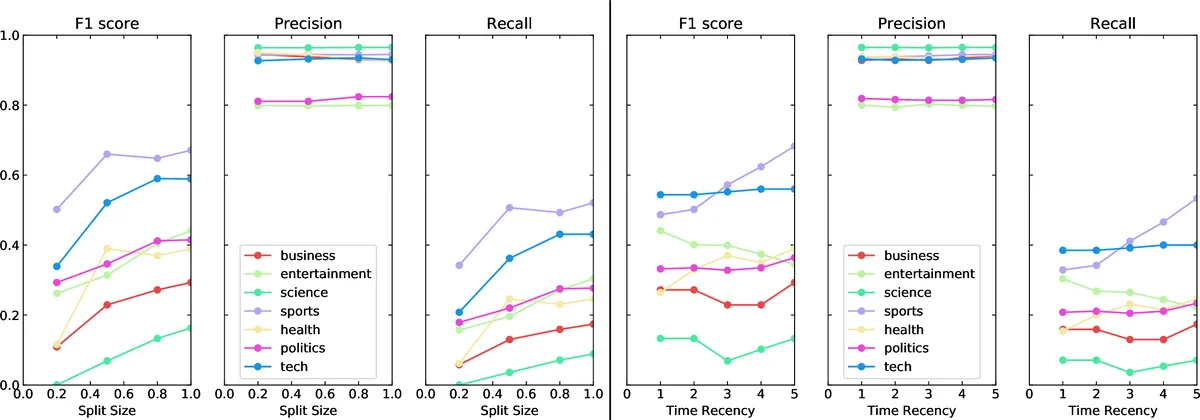
실험 설계는 두 축으로 나뉜다. 첫 번째는 학습 데이터 양을 늘려 과거부터 최신까지 포함했을 때 성능 변화를 관찰하는 것이고, 두 번째는 학습 데이터의 최신성만을 조절해 ‘시간적 가중치’를 적용하는 것이다. 시간 가중치는 지수 함수 (e^{(\log(p)\cdot i)/n}) 으로 정의했으며, p=10일 때 가장 큰 성능 향상을 보였다. 결과는 F1, 정밀도, 재현율 모두에서 학습 데이터가 많을수록, 그리고 최신 데이터에 더 높은 가중치를 줄수록 성능이 향상된다는 점을 일관되게 확인했다. 특히 ‘정치’, ‘비즈니스’, ‘기술’ 등 주요 주제에서는 노이즈 라벨을 사용한 경우에도 0.7 ~ 0.8 수준의 F1 점수를 달성했으며, 인간이 직접 라벨링한 골드 스탠다드에서도 비슷한 추세를 보였다.
주제 드리프트에 대한 분석에서는, 과거 데이터만을 사용했을 때 성능이 급격히 감소하는 현상이 관찰되었으며, 이는 트위터 상의 뉴스 사이클이 빠르게 변함을 반영한다. 그러나 최신 데이터에 가중치를 부여함으로써 이러한 드리프트를 효과적으로 보정할 수 있음을 실증하였다. 또한 ‘엔터테인먼트’와 같이 라벨이 다소 모호하거나 일반 계정에서 다양한 하위 주제가 섞여 있는 경우 F1 점수가 낮아지는 한계도 제시한다.
이 논문의 주요 공헌은 (1) 인간 큐레이션 계정을 활용한 ‘사실상 무료’ 라벨링 방법론, (2) 라벨 노이즈와 주제 드리프트를 동시에 고려한 학습 데이터 관리 전략, (3) 실시간 알림 서비스에 적용 가능한 경량화된 분류 모델 구현이다. 한계점으로는 라벨이 없는 일반 계정을 직접 활용하지 못한다는 점과, 영어 트윗에만 초점을 맞춘 점이 있다. 향후 연구에서는 다국어 확장, 라벨이 희소한 주제에 대한 데이터 증강, 그리고 사용자 맞춤형 토픽 프리퍼런스를 반영한 개인화 모델 구축이 제안된다.
댓글 및 학술 토론
Loading comments...
의견 남기기