단어 초두 문자와 내부 문자의 예측 가능성 차이
초록
연구는 영어 텍스트에서 글자 예측 가능성이 단어 내 위치에 따라 크게 달라진다는 것을 밝혀냈다. 첫 글자는 가장 예측이 어려워 엔트로피가 높고, 단어가 진행될수록 엔트로피가 감소한다. 내부 글자의 평균 엔트로피는 첫 글자에 비해 약 4배 낮다.
상세 분석
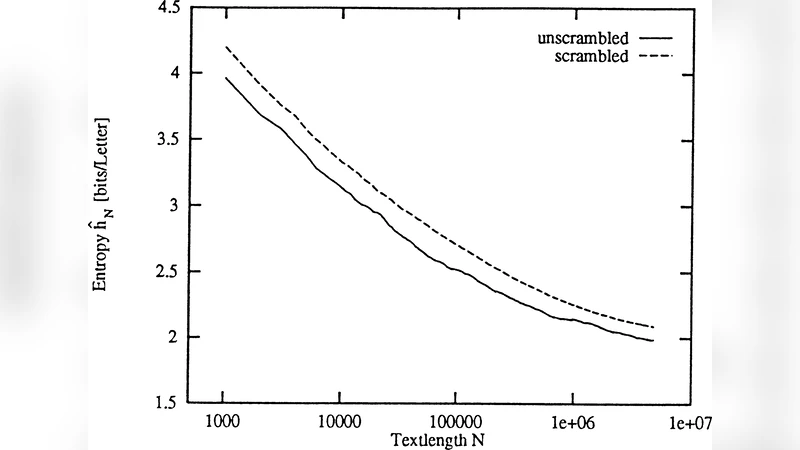
본 논문은 대규모 영어 코퍼스를 이용해 문자별 조건부 엔트로피를 계산함으로써, 단어 내 위치가 예측 가능성에 미치는 영향을 정량화하였다. 저자들은 PPM( Prediction by Partial Matching)과 같은 컨텍스트 기반 압축 알고리즘을 활용해 각 문자에 대한 사전 확률 분포를 추정하고, 이를 통해 위치별 엔트로피 H(i)=−∑p(c|context_i)log₂p(c|context_i)를 구하였다. 결과는 i=1(단어 첫 글자)에서 H≈4.5 bit, i≥3에서 H≈1.1 bit 정도로, 첫 글자의 엔트로피가 내부 글자보다 약 4배 높음을 보여준다. 이는 단어가 의미적·형태소적 단위로서 강한 내부 상관관계를 갖고, 단어 경계에서는 상관성이 급격히 약해진다는 가설을 실증적으로 뒷받침한다. 또한, 글자 수준의 마코프 모델 차수가 증가할수록 첫 글자 예측이 크게 개선되지 않으며, 이는 초기 컨텍스트가 충분히 제한적이기 때문임을 시사한다. 저자들은 이러한 현상이 인간의 언어 처리 메커니즘—예를 들어, 독자가 단어 초두에서부터 후보 단어 집합을 형성하고, 이후 글자를 통해 후보를 좁혀가는 과정—과도 일맥상통하다고 논한다. 더불어, 암호학적 관점에서 첫 글자의 높은 엔트로피는 텍스트 암호화 시 초기 키 스트림의 보안성을 강화하는 데 활용될 수 있음을 제안한다. 마지막으로, 자연어 처리(NLP) 모델 설계 시 단어 경계 정보를 명시적으로 활용하면, 특히 초반 토큰에 대한 예측 정확도를 크게 향상시킬 수 있음을 강조한다.
댓글 및 학술 토론
Loading comments...
의견 남기기