자동 키워드 추출 기반 텍스트 요약 연구 동향
초록
본 논문은 자동 키워드 추출이 텍스트 요약에 미치는 영향을 중심으로 최근 연구들을 종합적으로 조사한다. 키워드 추출 방법론을 통계‑기반, 언어학‑기반, 그래프‑기반, 머신러닝·딥러닝 기반으로 구분하고, 각 방법의 장·단점을 비교한다. 또한 요약에 활용되는 주요 데이터베이스와 평가 지표(Rouge, Precision·Recall 등)를 정리하고, 현재 직면한 문제점과 향후 연구 과제를 제시한다.
상세 분석
이 설문 논문은 자동 키워드 추출과 텍스트 요약 사이의 인과관계를 체계적으로 분석한다는 점에서 의미가 크다. 먼저 키워드 추출 기법을 네 가지 범주로 나누어 상세히 검토한다. 통계‑기반 방법은 TF‑IDF, χ², 정보이득 등 단어 빈도와 가중치를 활용해 간단하면서도 빠른 구현이 가능하지만, 문맥 정보를 충분히 반영하지 못한다는 한계가 있다. 언어학‑기반 접근은 형태소 분석, 품사 태깅, 명사구 추출 등을 통해 의미론적 정확성을 높이지만, 언어마다 다른 규칙과 사전 의존도가 높아 다국어 적용이 어려운 점이 있다. 그래프‑기반 방법은 TextRank, LexRank와 같이 단어 혹은 문장을 노드로 하여 연결 강도(공동출현, 의미 유사도)를 가중치로 삼아 중요도를 계산한다. 이 방식은 구조적 정보를 효과적으로 활용해 추출형 요약에 강점을 보이며, 최근에는 하이퍼그래프와 멀티레벨 그래프를 도입해 성능을 향상시키는 연구가 진행 중이다. 마지막으로 머신러닝·딥러닝 기반 방법은 지도학습을 위한 라벨링 데이터가 필요하지만, BERT, GPT, Transformer‑Encoder‑Decoder 구조 등을 이용해 문맥을 깊이 이해하고 추출·생성형 요약을 동시에 수행한다. 특히 사전학습 모델을 도메인 특화 데이터에 파인튜닝하는 전략이 최근 주목받고 있다.
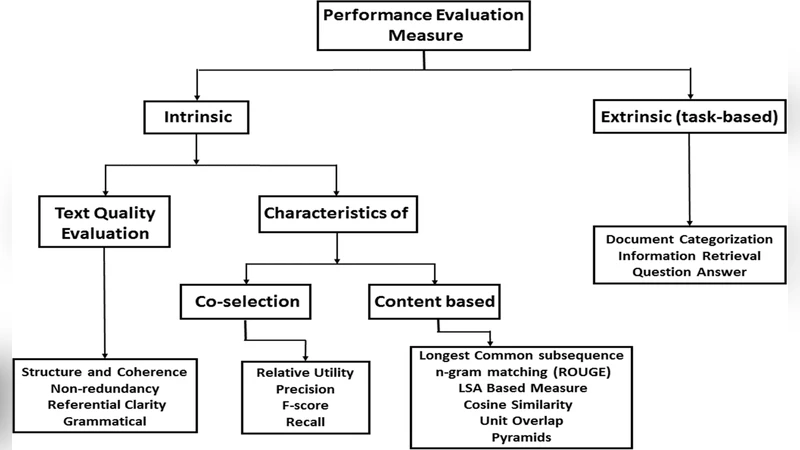
데이터베이스 측면에서는 DUC, TAC, CNN/DailyMail, XSum, Multi-News 등 다양한 요약 코퍼스를 소개하고, 각 코퍼스가 제공하는 요약 유형(추출 vs. 생성), 길이 제한, 도메인 특성 등을 비교한다. 평가 매트릭스는 ROUGE‑1/2/L, BLEU, METEOR, BERTScore 등 표면적 일치와 의미적 일치를 동시에 측정하는 지표를 포괄한다. 논문은 또한 인간 평가(가독성, 정보 충실도, 요약 일관성)와 자동 평가 간의 상관관계가 낮은 경우가 많아 평가 방법론의 개선 필요성을 강조한다.
문제점으로는 (1) 도메인 간 전이 학습의 어려움, (2) 다언어·다문화 텍스트에 대한 일반화 부족, (3) 추출형 요약의 경우 원문 문장의 순서와 연결성을 유지하지 못하는 경우가 잦음, (4) 평가 지표가 실제 사용자 만족도를 완전히 반영하지 못함을 들었다. 향후 연구 방향은 (①) 멀티모달(텍스트·이미지·오디오) 통합 요약, (②) 강화학습 기반 요약 정책 최적화, (③) 설명가능 AI를 통한 키워드·요약 결과의 투명성 확보, (④) 저자극(Zero‑Shot) 및 소량 학습(Few‑Shot) 기법을 활용한 도메인 적응, (⑤) 인간‑기계 협업 인터페이스 설계 등이다.
전반적으로 이 설문은 키워드 추출과 요약 기술의 최신 흐름을 포괄적으로 정리함으로써, 연구자들이 기존 방법의 한계를 인식하고 새로운 모델 설계에 필요한 인사이트를 제공한다.