머신러닝 모델의 회원 정보 유출 공격
본 논문은 블랙박스 API만을 이용해 머신러닝 모델에 학습된 개별 데이터 레코드의 존재 여부를 판단하는 “멤버십 추론 공격”을 제안하고, 구글·아마존 등 MLaaS 서비스에 적용해 높은 성공률을 보이며, 과적합 정도와 모델 설계가 위험 요인임을 실험적으로 입증한다. 또한 예측 결과 제한, 정밀도 감소, 엔트로피 증가, 정규화 등 완화 방안을 평가한다.
저자: Reza Shokri, Marco Stronati, Congzheng Song
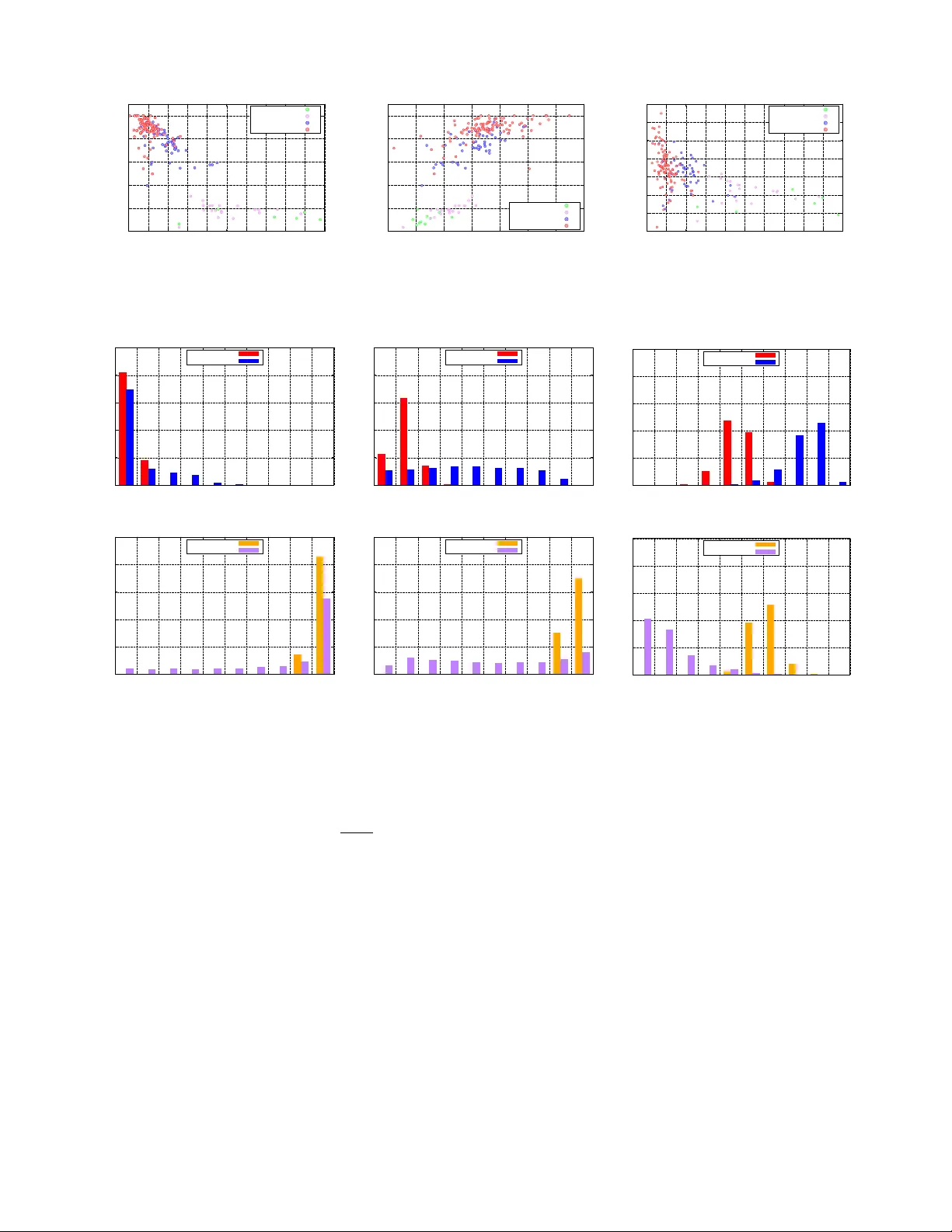
본 논문은 머신러닝 모델이 훈련 데이터에 대한 정보를 얼마나 누설하는지를 정량적으로 조사한다. 연구자는 ‘멤버십 추론’이라는 기본 공격을 정의한다. 공격자는 블랙박스 형태의 모델 API에 입력을 제공하고, 모델이 반환하는 클래스별 확률 벡터와 입력 레코드의 실제 라벨을 이용해 해당 레코드가 모델의 훈련 집합에 포함됐는지를 판단한다. 이를 위해 저자들은 ‘섀도우 학습(shadow training)’이라는 새로운 프레임워크를 제안한다. 섀도우 모델은 목표 모델과 동일한 학습 플랫폼(예: Google Prediction API, Amazon ML)을 사용하지만, 훈련 데이터는 공격자가 직접 제어한다. 섀도우 모델들을 다수 생성하고, 각 모델에 대해 입력‑출력 쌍을 수집한 뒤, 멤버(훈련 데이터)와 비멤버(테스트 데이터)를 라벨링한다. 이렇게 만든 데이터셋을 사용해 공격 모델을 학습시키면, 목표 모델에 대한 멤버십 추론이 가능해진다.
섀도우 데이터 생성 방법은 세 가지로 구분된다. 첫 번째는 목표 모델에 대한 무작위 쿼리를 통해 합성 데이터를 얻는 완전 블랙박스 방식으로, 사전 지식이 전혀 없는 상황에서도 적용 가능하다. 두 번째는 모집단 통계(특징 분포, 라벨 비율 등)를 활용해 가짜 훈련 데이터를 생성하는 방법이며, 이는 목표 모델의 데이터 분포에 대한 일부 사전 정보를 필요로 한다. 세 번째는 목표 모델 훈련 데이터의 노이즈 버전을 사전에 입수한 경우로, 가장 강력하지만 현실성은 낮다.
실험은 네 가지 실제 데이터셋(이미지, 소매 거래, 위치 추적, 병원 퇴원 기록)을 사용해 진행되었다. 구글과 아마존의 MLaaS 플랫폼을 통해 신경망, 결정 트리, 로지스틱 회귀 등 다양한 모델을 학습시켰으며, 모델 구조와 하이퍼파라미터는 전혀 알 수 없는 상황에서 공격을 수행했다. 결과는 다음과 같다.
- 10,000건 규모의 소매 거래 데이터에 대해 구글 모델은 94%의 멤버십 추론 정확도, 아마존 모델은 74%를 기록했다.
- 섀도우 데이터를 완전히 합성(첫 번째 방법)했음에도 구글 모델에 대한 정확도는 90%에 달했다.
- 텍사스 병원 퇴원 데이터(민감한 의료 정보)에서는 70% 이상의 정확도를 보였으며, 이는 환자 개인의 질병 여부 등 민감 정보를 노출시킬 위험을 의미한다.
공격 성공률은 모델의 과적합 정도와 강하게 연관된다. 과적합이 심한 모델은 훈련 데이터에 대해 높은 확신도를 보이며, 비멤버 데이터에 비해 확률 분포가 뚜렷하게 차이난다. 논문은 정규화(L1/L2), 드롭아웃, 조기 종료 등 과적합 방지 기법이 멤버십 누설을 감소시키는 효과를 정량적으로 입증한다. 또한 모델 출력 자체를 제한하는 완화 전략을 제안한다.
1. **Top‑k 제한**: 모델이 상위 k개의 클래스 확률만 반환하도록 하여, 낮은 확률값을 숨긴다.
2. **정밀도 감소**: 확률값을 소수점 이하 몇 자리만 제공해 정보량을 줄인다.
3. **엔트로피 증가**: 의도적으로 확률 분포를 평탄하게 만들어 모델이 특정 레코드에 대해 높은 확신을 보이지 않게 한다.
4. **정규화 및 드롭아웃**: 학습 단계에서 과적합을 억제해 멤버십 차이를 최소화한다.
이러한 완화 기법들은 공격 정확도를 일정 수준 이하(예: 60% 미만)로 낮출 수 있지만, 모델의 예측 정확도에도 영향을 미치는 트레이드오프가 존재한다. 특히 Top‑k 제한은 서비스 품질을 크게 저하시킬 수 있다.
결론적으로, 블랙박스 API만으로도 머신러닝 모델이 훈련 데이터의 존재 여부를 높은 정확도로 추론할 수 있음을 입증했으며, 특히 MLaaS 환경에서 데이터 제공자가 충분한 프라이버시 보호 조치를 취하지 않을 경우 심각한 개인정보 유출 위험이 존재한다는 점을 강조한다. 논문은 향후 차등 프라이버시와 같은 강력한 수학적 프레임워크를 적용한 방어 메커니즘 연구의 필요성을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기