비동기 분산 좌표 하강법으로 푸는 대규모 비볼록 파티셔닝 최적화
초록
본 논문은 네트워크 내 각 노드가 전체 변수의 일부만 담당하는 파티셔닝 구조와 빅데이터 규모를 갖는 비볼록 최적화 문제를 대상으로, 비동기식 가십 통신 위에서 동작하는 무작위 좌표 하강 알고리즘을 제안한다. 로컬 2차 근사와 프로시멀 연산을 이용해 각 노드가 독립적으로 업데이트하며, 이를 일반화된 좌표 하강 방법으로 해석해 확률적 수렴을 증명한다. 시뮬레이션을 통해 비볼록 2차 프로그램에서의 실효성을 확인한다.
상세 분석
이 논문은 “분산 파티셔닝(big‑data) 비볼록 최적화”라는 특수한 문제 설정을 명확히 정의한다. 전체 변수 x∈ℝⁿ은 N개의 블록 x_i 로 분할되고, 각 노드 i는 자신과 이웃 노드 j∈𝒩_i가 공유하는 변수만을 포함하는 로컬 함수 f_i(x_{𝒩_i})와 자체 변수에만 의존하는 비스무스함수 g_i(x_i)를 가진다. 이러한 구조는 변수‑함수 간의 희소성(sparsity)이 통신 그래프와 일치한다는 점에서 기존의 전역 합의(consensus) 방식보다 스케일링 효율이 높다.
알고리즘은 비동기식 타이머 기반 가십 프로토콜을 채택한다. 각 노드는 독립적인 지수분포 타이머 τ_i를 가지고, 타이머가 만료될 때 ‘awake’ 단계에서 로컬 2차 근사 q_i(s_i; \bar{x})를 최소화해 업데이트 방향 d_i를 구한다. 여기서 q_i는 현재 전체 상태 \bar{x}에 대한 강볼록 2차 근사이며, Q_i(·)는 L_i I 혹은 헤시안 근사 등으로 선택 가능하다. 업데이트 후 \bar{x}_i←\bar{x}i+d_i 와 함께 새로운 그라디언트 ∇{x_i}f_j ( j∈𝒩_i )를 이웃에 전파한다. ‘idle’ 단계에서는 수신된 그라디언트와 변수만을 저장하고 계산을 수행하지 않는다.
핵심 이론적 기여는 이 비동기 프로세스를 “일반화된 좌표 하강”으로 등가화한 점이다. 각 트리거를 하나의 전역 이터레이션 t 으로 매핑하고, 무작위 선택된 블록 i 에 대해 prox_{Q_i^{-1},g_i} 연산을 수행하는 형태로 재구성한다. 가정 II.1 (블록‑리프시츠 연속성)과 III.1 (Q_i ≥ L_i I) 덕분에 q_i가 강볼록함을 보장하고, 따라서 기대값 기준으로 V(·) 의 감소가 보장된다. 정리 IV.1 은 이러한 감소가 확률적으로 무한히 진행되어, 모든 클러스터 포인트가 V 의 임계점, 즉 정류점(stationary point)임을 증명한다. 비동기성에도 불구하고 전역 시계가 필요 없으며, 각 노드가 로컬 타이머만으로 알고리즘을 진행할 수 있다는 실용적 장점이 강조된다.
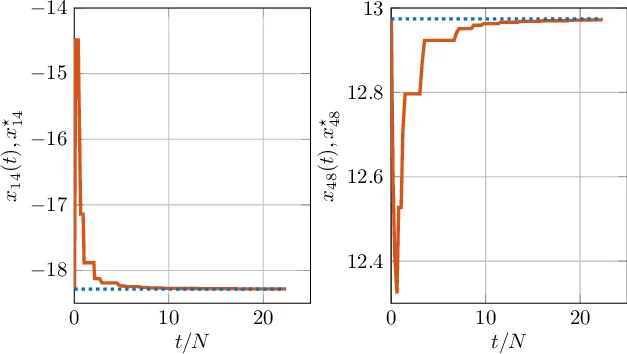
실험에서는 비볼록 2차 프로그램을 설정해, 제안 알고리즘이 기존 동기식 ADMM이나 좌표 하강법 대비 수렴 속도와 통신 효율에서 경쟁력을 보임을 확인한다. 특히, 변수 차원이 노드 수에 비례하는 경우에도 메모리·연산 부하가 선형적으로 증가함을 보여, 빅데이터 환경에서의 적용 가능성을 입증한다.
전체적으로 이 논문은 비동기식 가십 기반 분산 최적화에 좌표 하강과 프로시멀 기법을 결합함으로써, 비볼록·대규모 파티셔닝 문제에 대한 새로운 해법을 제시한다. 다만, 수렴이 정류점에 국한되고 수렴 속도에 대한 정량적 경계가 제한적이며, Q_i 선택에 따른 실험적 튜닝이 필요하다는 점은 향후 연구 과제로 남는다.
댓글 및 학술 토론
Loading comments...
의견 남기기