스웜 시스템을 위한 역강화학습: 동질성 활용한 단일 에이전트 축소와 이질적 학습 스킴
본 논문은 동질적인 대규모 다중 에이전트 시스템을 “swarMDP”라는 새로운 Dec‑POMDP 하위 모델로 정의하고, 에이전트 간 동질성으로 인해 다중 에이전트 역강화학습(IRL) 문제를 단일 에이전트 문제로 변환한다. 이를 기반으로 지역 가치와 Q‑함수를 이용한 이질적 학습 알고리즘을 제안하며, Ising 모델과 Vicsek 모델 실험을 통해 전역 행동을 재현하는 의미 있는 로컬 보상 함수를 성공적으로 학습한다.
저자: Adrian v{S}ov{s}ic, Wasiur R. KhudaBukhsh, Abdelhak M. Zoubir
본 논문은 “Inverse Reinforcement Learning (IRL) in Swarm Systems”라는 제목 아래, 대규모 동질적 다중 에이전트 시스템에 IRL을 적용하기 위한 새로운 이론적·알고리즘적 프레임워크를 제시한다. 서론에서는 자연계 스웜 현상이 중앙 제어 없이도 높은 견고성과 적응성을 보이는 이유를 ‘동질성’과 ‘국소 상호작용’으로 귀결시키며, 이러한 특성을 모델링하고 학습하기 위한 도구가 부족함을 지적한다. 기존 연구는 중앙 집중식 제어 가정이나 전역 상태 정보를 필요로 하는 제한적인 경우에만 적용 가능했으며, 진정한 분산 스웜에 대한 IRL은 아직 미비한 상태였다.
이를 해결하기 위해 저자는 “swarMDP”라는 새로운 Dec‑POMDP 하위 클래스(Decentralized Partially Observable Markov Decision Process)를 정의한다. swarMDP는 (N, A, T, ξ) 로 구성되며, N은 에이전트 수, A는 모든 에이전트가 공유하는 로컬 상태·관측·행동 집합, T는 전역 전이 확률, ξ는 전역 상태를 각 에이전트에 매핑하는 관측 함수이다. 핵심은 ξ와 T가 에이전트 순열에 대해 불변함을 요구함으로써, 초기 상태 분포가 순열 불변이면 전체 시스템이 시간에 따라 이 불변성을 유지한다는 점이다. 이 구조는 기존 Dec‑POMDP가 갖는 복잡성을 크게 줄이며, 동질성에 기반한 ‘교환 가능성(interchangeability)’을 명시적으로 모델링한다.
다음으로 IRL 문제를 다루는데, 일반적인 IRL은 “정책 업데이트 → 가치 추정 → 보상 업데이트”의 반복 과정을 가진다. 저자는 동질성 덕분에 ‘정책 업데이트’와 ‘가치 추정’ 단계만 에이전트 수준에서 수행하면 된다고 주장한다. 이를 위해 두 종류의 가치 함수를 정의한다. 첫 번째는 전역 상태 s에 기반한 프라이빗 가치 Vⁿ(s|π) 로, 전통적인 Bellman 방정식에 의해 정의된다. 그러나 에이전트는 전역 상태에 접근할 수 없으므로 실제 정책 설계에 부적합하다. 따라서 두 번째로 로컬 가치 Vⁿₜ(o|π)를 도입한다. 이는 현재 관측 o에 대한 전역 상태의 조건부 기대값을 사용해 정의되며, Proposition 1을 통해 모든 에이전트에 대해 동일함을 증명한다. 즉, 로컬 가치가 시간에 따라 수렴하면 단일 함수 V(o|π) 로 축소될 수 있다.
이제 정책 업데이트를 위해 ‘이질적 Q‑learning’ 알고리즘을 제안한다. 각 에이전트는 로컬 Q‑함수 Qⁿₜ(o,a|π)를 유지하고, 관측 o와 행동 a에 대한 기대 Q‑값을 업데이트한다. 학습 과정에서는 에이전트를 두 집합(탐험 집합 E와 탐욕 집합 G)으로 나누어, 초기에는 E 비율을 크게 잡아 다양한 로컬 상태를 탐색하게 하고, 학습이 진행될수록 E 비율을 점차 감소시켜 시스템이 정착된 동질적인 stationary behavior 로 수렴하도록 설계한다. 이 방식은 전통적인 다중 에이전트 Q‑learning이 겪는 비동기성·통신 비용 문제를 최소화하면서도 전역 목표를 달성한다.
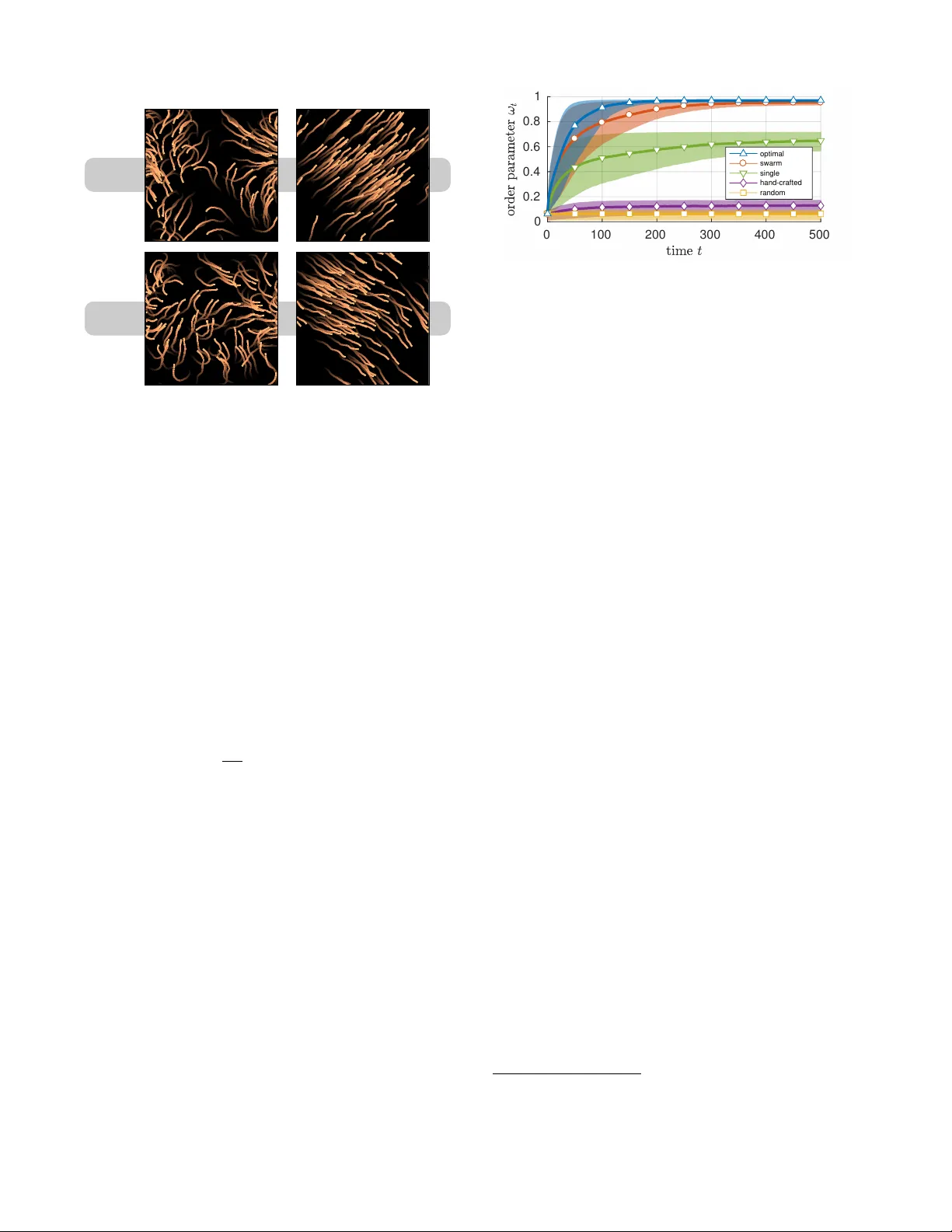
실험은 두 가지 대표적인 스웜 모델을 사용한다. 첫 번째는 이징 모델로, 각 에이전트가 이진 스핀을 가지고 인접 스핀과 상호작용하며 전역 에너지 최소화를 목표로 한다. 저자는 시뮬레이션으로부터 얻은 스핀 전이 궤적을 전문가 데이터로 사용하고, 제안된 IRL 프레임워크를 통해 로컬 보상 R(o) 를 학습한다. 학습된 보상과 로컬 정책을 적용했을 때, 재현된 스핀 동역학은 원본 시뮬레이션과 거의 일치하였다. 두 번째는 Vicsek 모델로, 자가 추진 입자들이 주변 이웃과 방향을 정렬하는 규칙을 따르며 전체적인 이동 방향을 형성한다. 여기서도 관측은 주변 입자들의 평균 방향이며, 학습된 로컬 보상은 입자들이 정렬을 유지하도록 유도한다. 실험 결과, 학습된 정책을 적용한 경우 전체 군집이 원본과 동일한 정렬도와 이동 패턴을 보였으며, 특히 초기 무질서 상태에서 정렬 상태로 전이되는 과정을 성공적으로 재현했다.
논문의 기여는 크게 세 가지로 요약된다. 첫째, 스웜 시스템을 위한 형식적 모델 swarMDP를 정의하고, 동질성에 기반한 순열 불변성을 명시함으로써 모델링 복잡성을 크게 감소시켰다. 둘째, 동질성으로 인해 다중 에이전트 IRL 문제를 단일 에이전트 문제로 엄격히 축소할 수 있음을 이론적으로 증명하였다(프라이빗 가치와 로컬 가치의 동등성). 셋째, 스웜 특성에 최적화된 이질적 Q‑learning 스킴을 설계하여, 실제 대규모 시스템에서도 효율적으로 로컬 보상을 학습하고 전역 행동을 재현할 수 있음을 실험적으로 입증했다.
마지막으로 논문은 몇 가지 제한점과 향후 연구 방향을 제시한다. 현재 모델은 완전한 동질성(모든 에이전트가 동일한 상태·관측·행동 집합)과 정적 관측 모델을 전제로 하며, 이질적인 에이전트나 동적 네트워크 토폴로지를 포함하는 경우는 다루지 않는다. 또한 로컬 가치의 수렴을 보장하기 위한 충분조건이 제한적이며, 비정상적인 환경 변화에 대한 적응성은 추가 연구가 필요하다. 향후 연구에서는 이질성, 동적 연결 구조, 그리고 부분 관측에 대한 베이지안 필터링을 결합한 확장된 swarMDP와, 심층 강화학습 기반의 함수 근사기를 활용한 대규모 연속 상태·행동 공간에 대한 확장 등을 탐색할 예정이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기