데이터 기반 대화 시스템 구축을 위한 공개 코퍼스 조사
본 논문은 데이터‑드리븐 대화 시스템 연구에 활용할 수 있는 공개 데이터셋을 포괄적으로 정리한다. 인간‑인간·인간‑기계 대화, 텍스트·음성·영상 등 다양한 형태와 규모의 코퍼스를 분류하고, 각 코퍼스가 대화 상태 추적, 의도 분류, 응답 생성 등 시스템 구성 요소 학습에 어떻게 기여할 수 있는지를 논의한다. 또한 전이학습, 외부 지식 결합, 평가 메트릭 선택 등에 대한 최신 연구 동향을 제시한다.
저자: Iulian Vlad Serban, Ryan Lowe, Peter Henderson
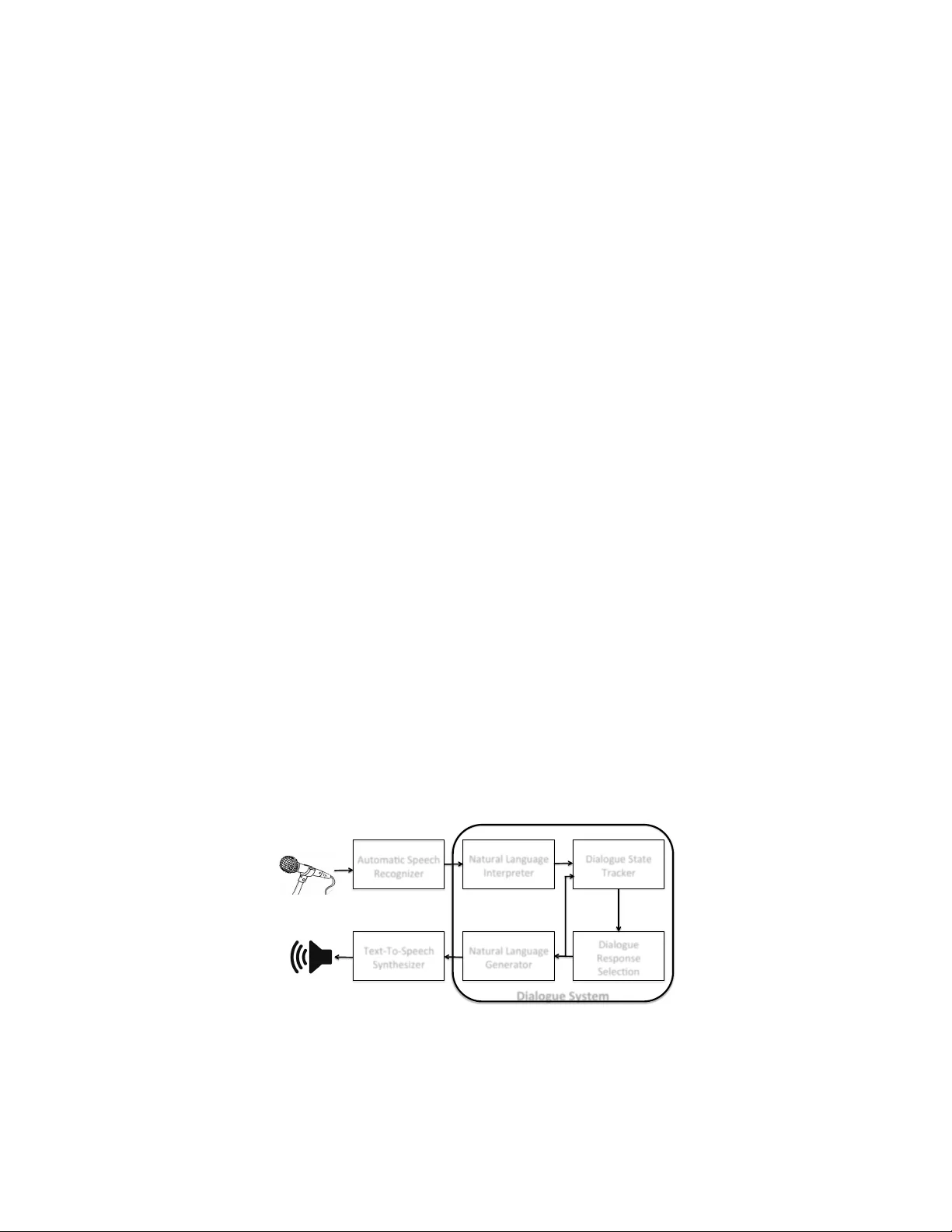
본 논문은 지난 10년간 음성·언어 이해 분야에서 데이터‑드리븐 모델이 가져온 혁신을 대화 시스템에 적용하려는 시도를 체계적으로 정리한다. 서론에서는 대화 시스템이 기술 지원, 언어 학습, 엔터테인먼트 등 다양한 응용 분야에 활용되고 있음을 언급하고, 기존 시스템이 여전히 규칙 기반 설계와 전문가 지식에 크게 의존하고 있음을 지적한다. 이후 데이터‑드리븐 접근법이 가능해진 배경으로 대규모 공개 코퍼스의 등장, GPU·클라우드 기반 연산 자원의 확대, 그리고 딥러닝·시퀀스‑투‑시퀀스 모델의 발전을 제시한다.
2장에서는 데이터‑드리븐 대화 시스템을 이해하기 위한 개념적 틀을 제공한다. 먼저 전통적인 대화 시스템 아키텍처(음성 인식, 언어 이해, 상태 추적, 응답 선택, 자연어 생성, 음성 합성)를 도식화하고, 각 모듈이 어떻게 학습 가능한 모델(분류·회귀·시퀀스 모델)로 대체될 수 있는지를 설명한다. 특히 자연어 이해와 생성은 일반 NLP 문제와 겹치므로, 기존의 대규모 언어 모델을 그대로 활용할 수 있음을 강조한다. 이어서 목표‑지향형과 비목표형 대화 시스템을 구분하고, 각각이 요구하는 데이터 특성(슬롯‑값 라벨링 vs. 자유 텍스트, 대화 성공 기준 등)을 상세히 논한다.
다음으로 2.3절에서는 각 모듈을 학습하기 위한 대표적인 감독학습 접근법을 소개한다. 의도 분류는 텍스트 → 라벨 매핑을 위한 다중 클래스 분류기로, 상태 추적은 슬롯‑값 조합을 예측하는 시퀀스 라벨링 혹은 CRF 모델로, 응답 선택은 대화 상태 → 응답 후보 매핑을 위한 다중 클래스 혹은 랭킹 모델로 구현될 수 있다. 자연어 생성은 템플릿 기반 혹은 신경망 기반 시퀀스‑투‑시퀀스 모델로 대체 가능하다.
2.4절에서는 엔드‑투‑엔드 신경망 모델을 개념적으로 정리한다. 입력으로 전체 대화 이력을 받아 바로 다음 발화를 생성하거나, 응답 후보를 점수화하는 구조를 제시하고, 이러한 모델이 데이터 양에 크게 의존한다는 점을 강조한다.
3장에서는 대화 코퍼스를 평가하는 기준을 제시한다. 대화 참여자 유형(인간‑인간, 인간‑기계), 언어 형태(텍스트, 음성, 영상), 대화 환경(자연스러운 일상 대화 vs. 제한된 도메인), 그리고 라벨링 수준(의도, 상태, 감정 등)의 네 축을 정의하고, 각 축이 데이터 활용 가능성에 미치는 영향을 분석한다. 특히 인간‑기계 대화는 목표‑지향형 시스템에, 인간‑인간 대화는 비목표형 챗봇 학습에 유리함을 설명한다.
4장에서는 실제 공개 코퍼스를 4가지 카테고리로 나누어 상세히 소개한다. (1) 텍스트 기반 인간‑인간 대화(예: Ubuntu Dialogue Corpus, Reddit Conversations, OpenSubtitles) – 대규모, 도메인 다양성, 라벨 부재; (2) 음성 기반 인간‑인간 대화(예: Switchboard, CALLHOME) – 음성·텍스트 동시 제공, 발화 경계 명확; (3) 인간‑기계 대화(예: DSTC 시리즈, ATIS, MultiWOZ) – 슬롯‑값 라벨링, 목표 지향, 도메인 제한; (4) 멀티모달·영상 대화(예: CMU-MOSI, AVSD) – 비언어적 신호 포함. 각 코퍼스에 대해 데이터 규모(대화 수, 발화 수, 토큰 수), 수집 방법(스크립트, 실제 콜센터, 크라우드소싱), 라벨링 비용, 공개 여부 등을 표로 정리한다.
5장에서는 데이터 활용 시 직면하는 핵심 이슈를 논의한다. 첫째, 코퍼스 규모와 품질의 트레이드오프; 대규모 일반 대화는 잡음이 많고 라벨이 없지만 사전학습에 유리하고, 소규모 도메인 특화 코퍼스는 라벨이 풍부하지만 일반화가 어려움. 둘째, 전이학습 전략 – 대규모 일반 코퍼스로 사전학습한 언어 모델(BERT, GPT 등)을 도메인 특화 코퍼스로 미세조정하거나, 다중‑도메인 멀티태스크 학습을 통해 도메인 간 지식을 공유하는 방법을 제시한다. 셋째, 외부 지식 통합 – 위키피디아, DBpedia, 도메인 데이터베이스 등을 활용해 사실 기반 응답을 생성하거나, 슬롯‑값 채우기에 사용한다. 넷째, 개인화와 상황화 – 사용자 프로필·대화 이력·시간·위치 정보를 모델에 포함시켜 맞춤형 응답을 생성하는 연구 동향을 소개한다. 마지막으로 평가 메트릭을 재검토한다. BLEU·ROUGE·METEOR와 같은 n‑gram 기반 자동 평가는 다중 정답이 존재하는 대화에서는 낮은 상관관계를 보이며, 대신 대화 성공률, 목표 달성 비율, 사용자 만족도 설문, 대화 길이, 대화 흐름 일관성 등 목표에 맞는 정량·정성 지표를 결합한 복합 평가 프레임워크를 권장한다.
결론(6장)에서는 데이터‑드리븐 대화 시스템 연구가 앞으로 나아가야 할 방향을 제시한다. 보다 풍부하고 다중 모달리티를 갖춘 코퍼스 구축, 라벨링 자동화·반자동화 도구 개발, 전이학습 및 멀티태스크 학습을 통한 데이터 효율성 향상, 그리고 인간 중심의 평가 방법론 정립이 필요하다고 강조한다. 전체적으로 이 논문은 대화 시스템 연구자들이 데이터 선택·전처리·학습·평가 전 과정을 체계적으로 설계할 수 있도록 포괄적인 로드맵을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기