가짜 리뷰 속 소크퍼펫을 찾아라
초록
본 연구는 한 사람이 여러 가명(소크퍼펫)을 사용해 작성한 가짜 리뷰를 탐지하는 방법을 탐구합니다. 작가의 문체적 언어 모델 간 KL-Divergence를 활용한 특징 선택 방법과, 훈련 데이터의 ‘스파이’ 샘플을 이용해 테스트 세트에서 숨겨진 유사/상이 샘플을 추출하는 ‘스파이 유도’ 방식을 제안합니다. 실제 소크퍼펫 데이터 실험을 통해 두 방법의 효과를 입증했습니다.
상세 분석
이 논문은 기만적 오피니언 스팸에서 소크퍼펫 탐지 문제를 저자 확인 및 검증 접근법으로 해결하고자 합니다. 핵심 기술적 통찰은 다음과 같습니다.
첫째, 소크퍼펫 탐지는 기존 리뷰 스팸 탐지와 근본적으로 다릅니다. 소크퍼펫은 하나의 사용자 ID를 극소수(종종 한 번)만 사용하므로, ID별 컨텍스트가 제한되어 기존 행위 기반 방법으로 탐지하기 어렵습니다. 따라서 문제는 주어진 작가(a)가 새로운 리뷰를 작성했는지 판단하는 ‘저자 검증’ 문제로 환원됩니다.
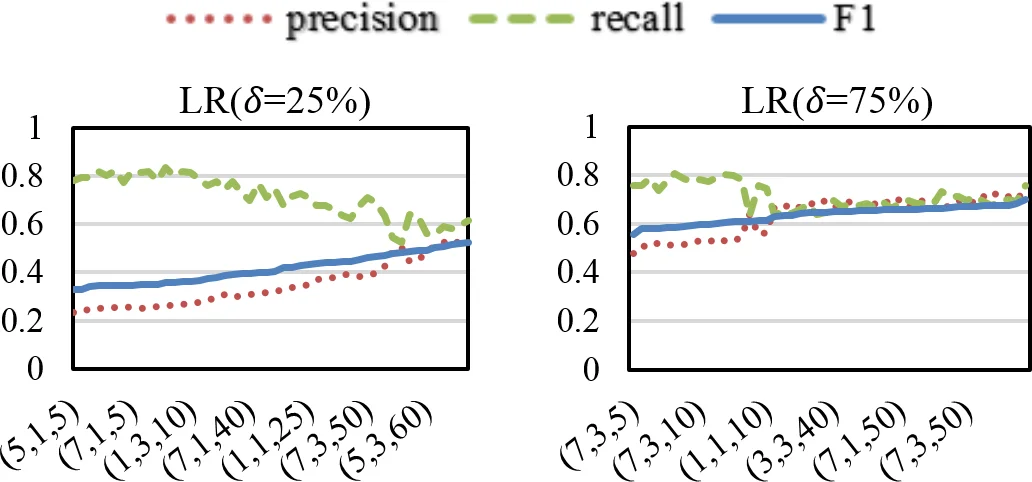
둘째, 실험을 통해 부정 클래스(¬a, 즉 작가 a가 아닌 다른 모든 사람)의 다양성과 크기가 증가할수록 검증기의 정밀도가 급격히 하락함을 확인했습니다. 이는 검증기가 보편적인 부정 클래스를 제대로 학습하지 못해 위양성이 증가함을 의미하며, 문제의 난이도를 보여줍니다.
이에 대한 해법으로 두 가지 혁신적 방법을 제시합니다.
- ΔKL-PTFs (특징 하위 샘플링): 작가 a와 부정 집합 ¬a의 스타일리스틱 언어 모델(파스 트리 특징으로 구성) 간 KL-Divergence를 계산합니다. 두 분포 간 차이에 가장 크게 기여하는 파스 트리 특징(PTF)들을 선택함으로써 고차원의 모든 특징을 사용하는 대신, 작가를 변별하는 핵심 스타일 요소만으로 저차원에서 모델을 학습합니다. 이는 데이터 희소성 문제를 완화하고 모델의 일반화 성능을 높입니다.
- 스파이 유도 (전이 학습): 훈련 세트의 작가 a 리뷰 중 일부를 ‘스파이’로 선정해 레이블이 없는 테스트 세트에 삽입합니다. 그런 다음 이 스파이들의 최근접 이웃(잠재적 긍정 샘플)과 최원점 이웃(잠재적 부정 샘플)을 테스트 세트에서 추출하여 훈련 데이터를 보강합니다. 이 방법은 제한된 훈련 데이터의 다양성과 크기 문제를 해결하며, 기존의 전체 테스트 세트를 사용하는 전이 학습과 달리 샘플링을 통해 효율성을 높입니다.
실험 결과, 두 방법 모두 기존 기준선을 크게 상회하는 성능을 보였으며, 특히 스파이 유도 방식은 다양한 분류기와 크로스 도메인 설정에서도 강건한 성능을 입증했습니다. 이는 소크퍼펫 검증이 낮은 차원의 변별적 스타일 특징과 테스트 세트의 잠재적 구조를 활용할 때 효과적으로 해결될 수 있음을 시사합니다.
댓글 및 학술 토론
Loading comments...
의견 남기기