위키리크스 외교전선 텍스트 보안 분류: 군집 기반 학습이 토픽 정제보다 우수
초록
본 논문은 위키리크스에서 공개된 미국 외교 전선 케이블을 대상으로 두 가지 자동 보안 분류 기법을 비교한다. 하나는 군집별 로컬 학습(A CESS)이고, 다른 하나는 토픽 모델을 이용해 훈련 데이터를 정제하는 방법이다. 동일한 평가 프로토콜 하에 실험한 결과, 군집 기반 학습이 토픽 정제 방식을 능가하며, 두 방법 모두 전통적인 SVM·NB·LR 등 베이스라인보다 높은 정확도를 보였다.
상세 분석
이 연구는 텍스트 보안 분류를 문서 수준과 단락 수준으로 명확히 구분하고, 각각의 특성에 맞는 피처 설계와 학습 전략을 제시한다. 문서 기반 접근은 전체 문서의 피처를 하나의 벡터로 합성해 단일 라벨을 예측하지만, 실제 외교 케이블은 대부분이 ‘UNCLASSIFIED’이며 소수의 민감한 단락만이 높은 보안 등급을 갖는다. 따라서 문서 전체에 동일 라벨을 부여하면 불필요한 노이즈가 포함돼 분류 성능이 저하될 위험이 있다. 논문은 이를 해결하기 위해 단락별 피처를 별도로 추출하고, 문서 라벨을 가장 높은 보안 등급 단락으로 정의하는 ‘단락 기반’ 방식을 채택한다. 이때 클래스 불균형 문제가 심각해지는데, 특히 ‘CONFIDENTIAL’과 ‘SECRET’ 사이의 혼동이 빈번하다. 저자는 균등 사전 확률을 가정한 확률 모델을 통해 이러한 현상을 정량화하고, 실제 데이터에서는 클래스 비율이 크게 왜곡되므로 사후 확률을 조정해야 함을 강조한다.
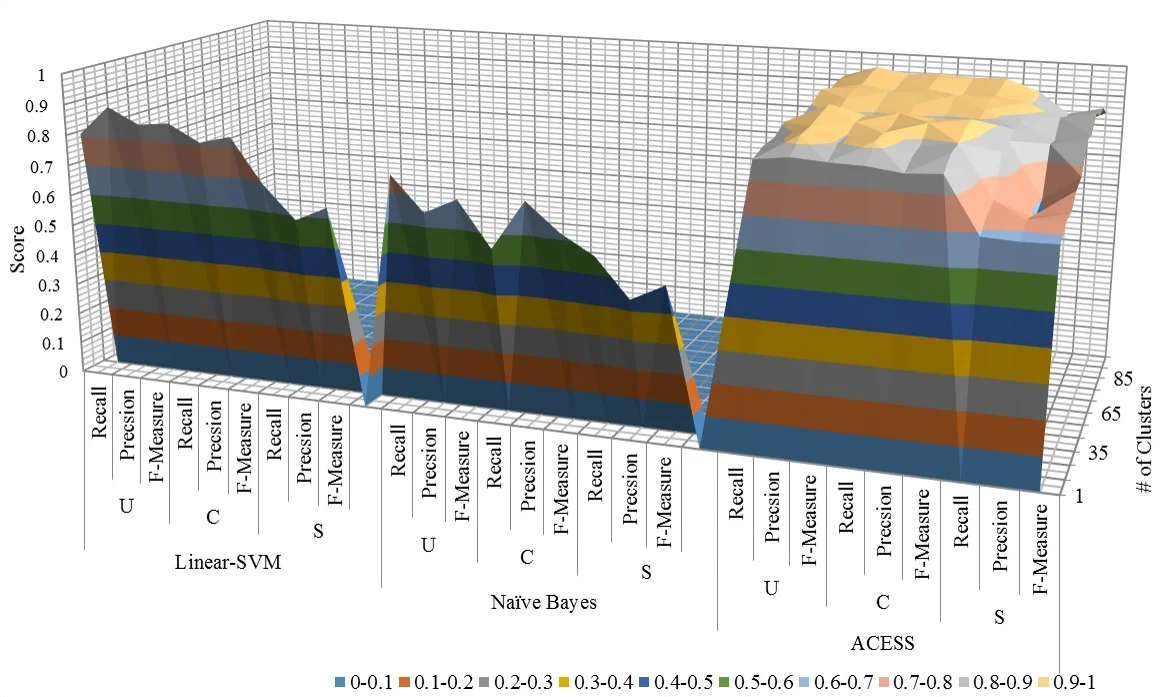
두 가지 핵심 알고리즘은 다음과 같다. 첫 번째인 A CESS(Automated Classification Enabled by Security Similarity)는 문서들을 의미적 유사도 기반 군집으로 나눈 뒤, 각 군집에 특화된 로컬 분류기를 학습한다. 군집화 단계에서는 TF‑IDF 벡터와 코사인 유사도를 사용해 k‑means 혹은 계층적 군집화를 수행하고, 군집 내 데이터가 상대적으로 동질적이므로 로컬 모델이 전역 모델보다 더 정밀한 경계 를 학습한다. 두 번째인 토픽 모델 정제는 LDA 기반 토픽을 두 차례 추출한다. 첫 번째 추출에서는 ‘메인 토픽’을 얻고, 여기서 ‘CONFIDENTIAL’과 ‘SECRET’(또는 ‘UNCLASSIFIED’와 ‘CONFIDENTIAL’) 비율이 사전에 정의한 임계값(베를린 기준) 사이에 있으면 해당 토픽을 ‘불순’이라고 판단한다. 불순 토픽에 속한 문서는 훈련 집합에서 제거하고, 남은 데이터로 서브 토픽을 다시 학습해 동일 과정을 반복한다. 이렇게 정제된 데이터는 클래스 혼합도가 낮아 학습 효율이 향상된다.
실험은 위키리크스 데이터셋을 네 개의 대사관(바그다드, 런던, 베를린, 다마스쿠스) 별로 별도 파티션을 만들어 수행했으며, 각 파티션은 최대 5만 개 단락을 포함한다. 평가 지표는 정확도, 정밀도, 재현율, F1‑score이며, 특히 ‘SECRET’ 클래스에 대한 재현율이 중요한 보안 관점에서 강조된다. 결과는 A CESS가 평균 정확도 0.89, F1 0.86을 기록해 토픽 정제(정확도 0.84, F1 0.80)보다 우수했으며, 두 방법 모두 SVM(정확도 0.73), Naïve Bayes(0.68), Logistic Regression(0.71)보다 현저히 높은 성능을 보였다. 특히 문서‑단락 혼합이 심한 경우, 로컬 군집 학습이 불순 토픽 제거만으로는 해결되지 않는 미세한 의미 차이를 포착하는 데 강점을 보였다.
하지만 논문에는 몇 가지 한계도 존재한다. 첫째, 피처는 전통적인 Bag‑of‑Words와 TF‑IDF에 국한돼 최신 딥러닝 기반 임베딩(BERT, RoBERTa 등)의 활용 가능성을 탐색하지 않았다. 둘째, 군집 수(k)와 토픽 수(K)의 하이퍼파라미터 선택이 데이터셋에 민감하게 작용함에도 불구하고, 검증 세트를 별도로 두지 않아 과적합 위험이 있다. 셋째, 실시간 적용을 위한 연산 복잡도 분석이 부족해 실제 DLP 시스템에 통합하기 위한 최적화 방안이 제시되지 않았다. 마지막으로, 데이터는 위키리크스 공개 자료에 한정돼 실제 정부 내부망에서 발생하는 다양한 포맷(메일, 보고서, 채팅 로그 등)과는 차이가 있다.
향후 연구 방향으로는 (1) 사전 학습된 언어 모델을 활용해 문맥 정보를 강화하고, (2) 군집과 토픽을 결합한 하이브리드 프레임워크를 설계해 각각의 장점을 통합, (3) 온라인 학습 및 스트리밍 환경에서의 효율적인 업데이트 메커니즘을 구축, (4) 다중 라벨 및 계층적 라벨링을 지원해 ‘CONFIDENTIAL’ 이하의 세부 등급을 세분화하는 방안을 제시한다. 이러한 개선은 내부자 위협 탐지와 실시간 데이터 유출 방지(DLP) 시스템의 정확도와 반응 속도를 동시에 높이는 데 기여할 것이다.
댓글 및 학술 토론
Loading comments...
의견 남기기