코드 스니펫 추천을 위한 정보검색과 지도학습 결합
초록
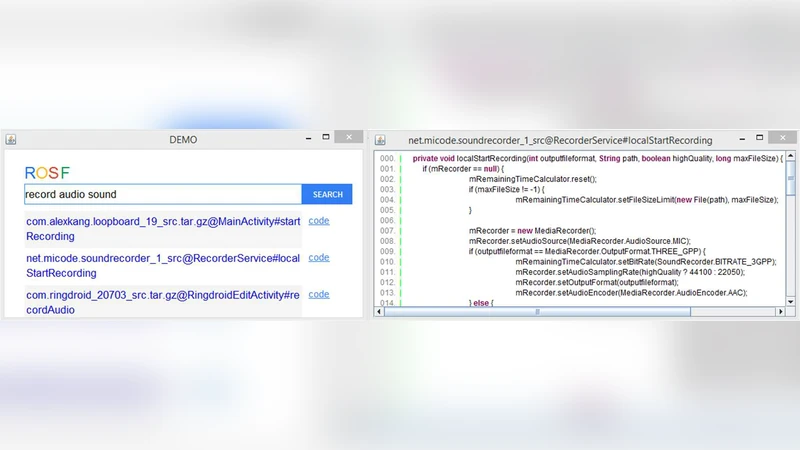
ROSF는 자유형 질의에 대해 대규모 코드 스니펫 저장소에서 후보를 IR 방식으로 빠르게 추출하고, 다중 특성을 활용한 지도학습 모델로 후보를 재정렬하여 상위 K개의 관련성 높은 코드를 추천한다. 실험 결과 기존 IR 기반 방법보다 정밀도 20‑41%·NDCG 13‑33% 향상을 보였다.
상세 분석
본 논문은 개발자가 새로운 프로그래밍 과제를 수행할 때 코드 예제를 검색하고 재사용하는 과정을 지원하기 위해, 전통적인 정보검색(IR) 기법과 지도학습 기반 순위 모델을 결합한 ROSF 프레임워크를 제안한다. ROSF는 두 단계로 구성된다. 첫 번째 단계인 ‘거친 검색(coarse‑grained searching)’에서는 BM25와 같은 전통적인 IR 스코어를 이용해 대규모 코드 스니펫 코퍼스(총 921 713개)에서 질의와 텍스트적으로 유사한 후보 집합을 빠르게 추출한다. 이때 질의는 자유형 자연어 혹은 키워드 형태일 수 있으며, 코드 스니펫은 주석, 메서드 시그니처, 내부 변수명 등을 모두 색인한다. 두 번째 단계인 ‘미세 재정렬(fine‑grained re‑ranking)’에서는 후보 집합에 대해 다중 측면 특성을 추출한다. 주요 특성은 (1) 텍스트 유사도(질의‑주석, 질의‑코드 토큰 간 코사인 유사도), (2) API 사용 패턴(호출된 메서드·클래스의 빈도와 질의와의 교집합 비율), (3) 구조적 메트릭(코드 길이, 복잡도, 제어 흐름 그래프 특징), (4) 문맥적 신호(스니펫이 포함된 파일·프로젝트의 인기 정도) 등이다. 이러한 특성들을 입력으로 사용해 로지스틱 회귀, 랜덤 포레스트, 혹은 Gradient Boosting Machine 등 여러 지도학습 알고리즘을 실험했으며, 최종 모델은 각 후보 스니펫에 대해 ‘관련성 점수’를 확률 형태로 예측한다. 예측 확률이 높은 순으로 후보를 재정렬하고 Top‑K를 최종 추천 결과로 제공한다.
학습 데이터는 개발자들이 실제로 검색하고 선택한 코드 예제를 라벨링하여 구축했으며, 라벨은 0~4의 5단계 관련성 스코어로 정의된다. 모델 학습 시 교차 검증을 통해 과적합을 방지하고, 특성 중요도 분석을 통해 API 사용 패턴과 텍스트 유사도가 가장 큰 영향을 미치는 것으로 확인되었다.
평가에서는 Precision@K와 NDCG@K를 주요 지표로 사용했으며, 기존 IR‑only 방법, 코드 검색 엔진(예: GitHub Code Search), 그리고 최신 딥러닝 기반 코드 검색 모델과 비교했다. ROSF는 모든 K값에서 평균 Precision을 20‑41% 향상시켰고, NDCG에서도 13‑33%의 개선을 기록했다. 특히 K가 작을수록(Top‑1, Top‑3) 재정렬 단계의 효과가 크게 나타났으며, 이는 실무에서 개발자가 가장 먼저 보는 결과의 품질을 크게 높일 수 있음을 의미한다.
또한, 실험을 통해 후보 집합의 크기와 재정렬 비용 사이의 트레이드오프를 분석했으며, 후보를 200~500개 정도로 제한할 경우 실시간 응답 시간(≈200 ms) 내에 재정렬이 가능함을 보였다. 이는 ROSF가 실제 IDE 플러그인이나 웹 기반 코드 검색 서비스에 적용될 수 있는 실용성을 갖춘다는 점을 시사한다.
결론적으로, ROSF는 단순 텍스트 매칭에 의존하는 기존 코드 검색 방법의 한계를 극복하고, 다중 특성을 활용한 지도학습을 통해 개발자에게 보다 정확하고 실용적인 코드 스니펫을 제공한다는 점에서 의미 있는 진보를 이룬다.
댓글 및 학술 토론
Loading comments...
의견 남기기