가중치 랜덤 워크 샘플링을 활용한 다중 관계 추천 시스템
초록
본 논문은 사용자-아이템 상호작용이 다양한 관계로 구성된 이종 정보 네트워크에서의 추천 문제를 다룹니다. 기존 연구가 가중치 정보(예: 평점)를 무시하거나 이진화하여 정보 손실이 발생하는 한계를 지적하며, 간선 가중치에 비례하여 샘플링 확률을 조정하는 ‘가중치 랜덤 워크 샘플링’ 방법을 제안합니다. 이 방법을 통해 생성된 확장 메타 경로를 다중 관계 행렬 분해 모델에 통합하여, Yelp, Book Crossing, MovieLens 데이터셋에서 기존 방법 대비 향상된 추천 정확도와 모델 생성 효율성을 입증합니다.
상세 분석
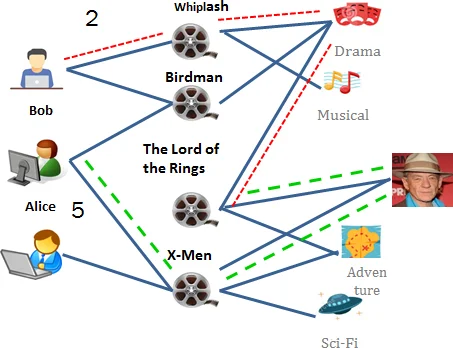
이 논문의 핵심 기술적 기여는 가중치가 부여된 이종 네트워크(Heterogeneous Information Network, HIN)에서 메타 경로를 생성하는 새로운 샘플링 기법입니다. 기존 메타 경로 확장 방법은 모든 가능한 경로를 탐색하거나(unweighted breadth-first), 가중치를 이진화하여 중요한 선호도 정보(예: 높은 평점과 낮은 평점의 차이)를 상실했습니다. 저자들이 제안하는 알고리즘(Algorithm 1)은 메타 경로를 따라 랜덤 워크를 수행할 때, 다음 노드로 이동할 간선을 선택하는 방식을 다르게 설계합니다. 특히, 사용자-아이템 관계와 같이 가중치가 의미 있는 간선 타입에 대해서는 ‘WSample’ 함수를 호출하여, 간선 가중치 w에 대해 e^w에 비례하는 확률로 샘플링을 수행합니다. 이는 높은 평점을 가진 아이템으로의 경로가 더 자주 탐색되도록 유도하여, 사용자의 강한 선호도를 메타 경로에 효과적으로 반영합니다. 반면, 아이템-장르 관계와 같은 보조적이고 가중치가 없는(unweighted) 간선 타입에 대해서는 균일한 샘플링(‘USample’)을 적용합니다.
이 방법의 주요 장점은 두 가지입니다. 첫째, 의미 있는 가중치 정보를 보존하면서도 계산 효율성을 확보했습니다. 모든 경로를 생성하는 것은 조합적으로 증가하는 계산 비용이 문제지만, 샘플링을 통해 이 비용을 크게 줄이면서도 통계적으로 유의미한 경로 집합을 얻을 수 있습니다. 둘째, 방법론의 유연성입니다. 알고리즘은 가중치 간선이 메타 경로의 어느 위치에出现하든 적용 가능하도록 설계되었으며, 다중 관계 행렬 분해(DMF)뿐만 아니라 다양한 다중 관계 추천 모델과 결합될 수 있는 일반성을 가집니다.
실험 결과는 제안 방법(Weighted Sampling + DMF)이 동일한 DMF 모델에 기존의 무가중치 메타 경로 확장 방법을 사용했을 때보다 세 가지 실세계 데이터셋에서 consistently 높은 정확도(Recall, Precision)를 기록했음을 보여줍니다. 또한, P3α, RP3β, HeatS/ProbS(HL) 같은 최신 그래프 기반 랜덤 워크 추천 알고리즘들과 비교해서도 우수한 성능을 달성했습니다. 이는 단순한 그래프 구조뿐만 아니라 관계의 의미와 강도를 함께 고려하는 모델링의 중요성을 입증합니다. 논문에서 언급한 향후 과제인 ‘다중 가중치 간선’을 가진 메타 경로 처리와 더 다양한 도메인에 대한 적용은 이 연구의 확장 가능성을 시사합니다.
댓글 및 학술 토론
Loading comments...
의견 남기기