단어 임베딩 모델의 일관된 정렬 방법
초록
본 논문은 동일하거나 서로 다른 단어 임베딩 모델들을 저차원 잠재 공간에 일관되게 정렬하기 위해, 고차원 임베딩 공간에서 선형 연산으로 생성한 인공적인 ‘잠재 단어’를 활용하는 방법을 제안한다. 생성된 잠재 단어를 앵커 포인트로 사용해 manifold alignment를 수행하고, trustworthiness와 continuity 지표를 통해 정렬 품질이 향상됨을 실험적으로 입증한다.
상세 분석
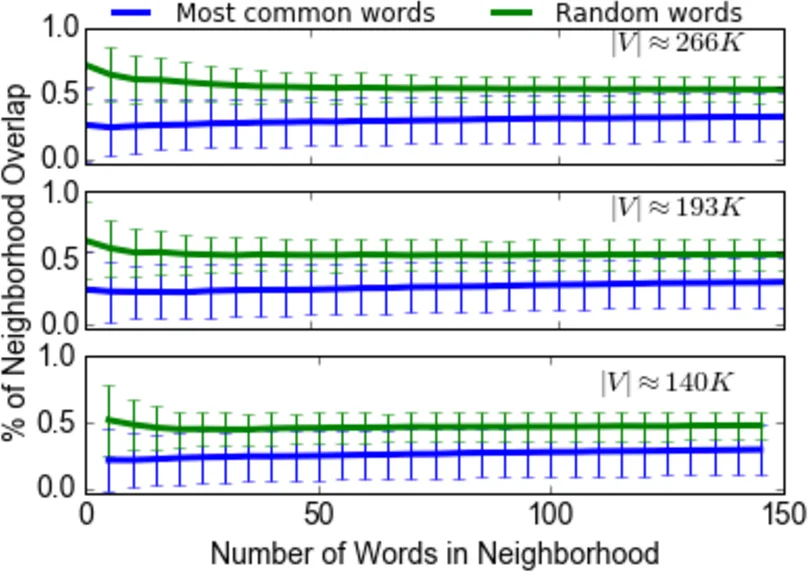
이 연구는 기존 워드 임베딩이 고차원에서 불안정하고, 동일 데이터셋을 사용하더라도 재학습 시 지역 이웃 구조가 크게 변한다는 문제점을 먼저 실증한다. 특히 Wikipedia 2016 데이터를 140K, 193K, 260K 규모의 어휘집합으로 나누어 200차원 임베딩을 학습한 뒤, 동일 파라미터로 여러 번 재학습했을 때 이웃 겹침 비율이 낮아지는 현상을 관찰한다. 이러한 불안정성은 차원 축소와 모델 간 비교·통합을 어렵게 만든다.
논문은 두 가지 핵심 아이디어로 이를 해결한다. 첫째, 고차원 임베딩이 선형 연산(예: king‑woman+man=queen)으로 의미 관계를 표현한다는 사실을 이용해, 기존 이웃 내 단어들의 선형 결합으로 ‘잠재 단어’를 생성한다. 여기서 α는 −1~+1 사이의 정수이며, 생성된 벡터가 원 이웃 반경 ε 안에 있으면 유효한 잠재 단어로 채택한다. 이러한 잠재 단어는 실제 어휘가 아니어도, 고차원 공간에서 기대되는 위치에 존재한다는 가정 하에 앵커 포인트 역할을 한다.
둘째, 이러한 앵커를 포함한 확장된 점군에 대해 저차원 manifold alignment 기법인 Low Rank Alignment(LRA)를 적용한다. LRA는 기존의 Locally Linear Embedding(LLE)을 확장한 방법으로, 여러 모델의 공통 이웃을 기반으로 공동 잠재 공간을 구축한다. 정렬 품질 평가는 van der Maaten이 제안한 trustworthiness(T)와 continuity(C) 지표를 사용한다. 실험 결과, 잠재 단어를 추가했을 때 T와 C 값이 특히 12개 이하의 이웃에서는 미세하게 개선되고, 이웃 수가 늘어날수록 정렬 성능이 크게 상승한다. 또한, 빈도가 높은 단어일수록 개선 폭이 크다는 점도 확인했다.
이 접근법의 장점은 (1) 기존 모델을 재학습하거나 추가 데이터가 필요 없으며, (2) 서로 다른 차원·구조를 가진 임베딩을 동일한 저차원 공간에 통합할 수 있다는 점이다. 그러나 잠재 단어 생성 과정이 임의성(α 선택)에 의존하고, 선형 관계가 모든 의미 관계를 포착하지 못한다는 한계가 남는다. 향후 연구에서는 전체 어휘에 대한 전역 정렬, 잠재 단어 가중치를 손실 함수에 포함하는 정규화, 그리고 다양한 도메인·언어에 대한 일반화 검증이 필요하다.
댓글 및 학술 토론
Loading comments...
의견 남기기