CMAC 40년 연구 여정: 뇌 영감 모델의 진화와 미래
초록
본 리뷰는 1970년대 초창기 제안된 Cerebellar Model Articulation Controller(CMAC)의 40년간 발전 과정을 정리한다. 모델을 신경망 관점과 테이블 조회 기법 두 가지 시각으로 바라보고, 구조 변화, 학습 알고리즘, 주요 응용 분야를 체계적으로 정리한 뒤, 현재 남아 있는 한계와 향후 연구 방향을 제시한다.
상세 분석
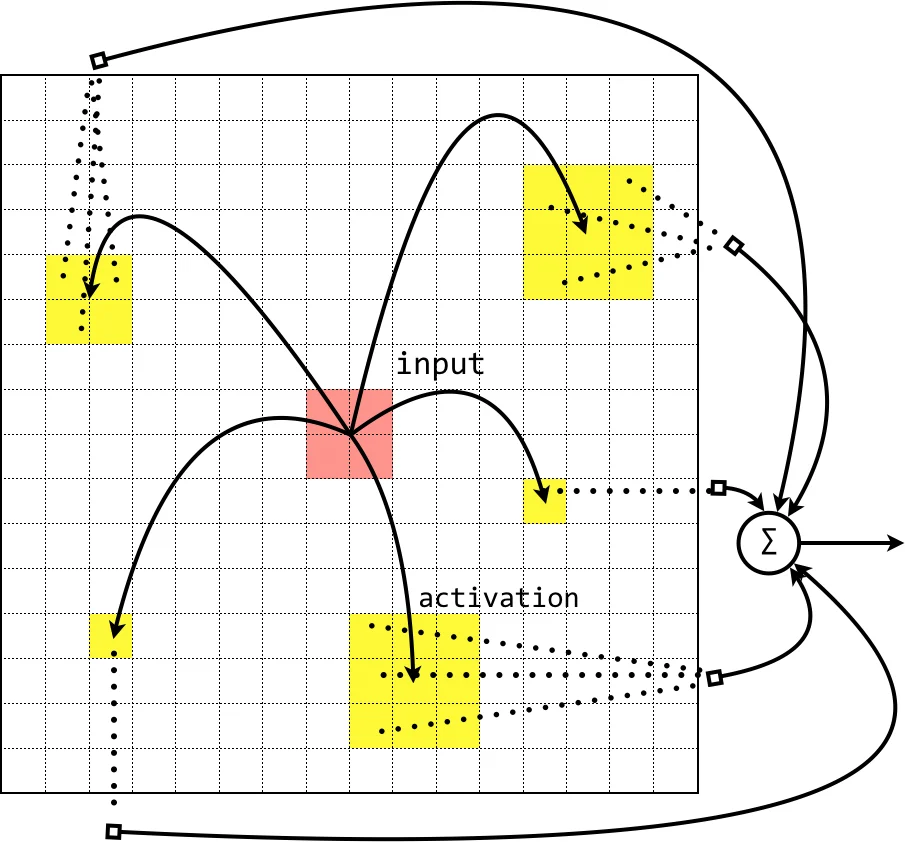
CMAC은 초기에는 알버스가 제안한 두 단계 매핑(감각‑연관‑출력) 구조를 갖는 테이블 기반 근사기법으로 시작했다. 입력 공간을 격자화하고 인접한 연관 셀만 활성화함으로써 학습 속도를 크게 높였지만, 차원 폭증과 메모리 요구량이 급증하는 ‘차원의 저주’ 문제가 발생한다. 이를 해결하기 위해 타일 코딩, 해싱, 그리고 가중치 압축 기법이 도입되었으며, 특히 해싱은 가상 주소 공간을 물리적 메모리로 매핑해 저장 효율을 크게 개선했지만 충돌 관리가 여전히 난제였다. 구조적 측면에서는 개념 메모리(Conceptual Memory)를 추가한 2‑계층 모델, 다중 CMAC을 계층적으로 결합한 Cascade 및 Hierarchical CMAC, 그리고 고차원 spline·fuzzy·linguistic 변형이 제안되었다. 고차 CMAC은 spline 함수를 이용해 연속적인 미분 가능성을 부여해 근사 정확도를 높였으며, LC‑CMAC과 FC‑CMAC은 라벨 의미와 퍼지 멤버십을 도입해 입력‑출력 관계를 확률·퍼지 방식으로 기술한다. 학습 알고리즘은 알버스식 역전파 기반 고정 학습률에서 시작해, 초기 큰 α를 점진적으로 감소시키는 Adaptive Learning Rate, 가중치 스무딩, Credit Assignment(활성 횟수 기반 가중치 신뢰도 조정) 등 안정성과 수렴 속도를 동시에 개선하는 기법으로 확장되었다. 또한 모멘텀, 이웃 학습, 평균 퍼지 출력 등을 결합한 MC‑CMAC, SOFM‑형태의 경쟁 학습 등 신경망 이론과의 융합 시도가 이루어졌다. 이러한 변형들은 모두 CMAC이 실시간 제어, 로봇 팔, 프린터 보정, 비선형 시스템 추정 등 다양한 분야에서 빠른 적응성과 저연산량을 요구하는 응용에 적합하도록 만든다. 그러나 여전히 가중치 수 폭증, 희소 데이터에서의 보간 오류, 이산 모델의 미분 불가능성 등 구조적 한계가 존재한다. 최근 빅데이터와 고성능 컴퓨팅 환경에서도 제한된 메모리와 실시간 요구조건을 만족해야 하는 임베디드 시스템에서는 효율적인 압축·계층 구조 설계와 학습률 자동 조정 메커니즘이 핵심 과제로 남아 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기