대규모 컴퓨팅 시스템을 위한 견고한 비동기 뉴턴 방법
초록
본 논문은 자원봉사형 그리드 환경에서 비동기적으로 실행되는 뉴턴 기반 로컬 최적화 알고리즘을 제안한다. 기존의 진화적 알고리즘을 비동기화한 FGDO 프레임워크에 비동기 뉴턴(ANM)을 확장함으로써, 이질적이고 불안정한 노드에서도 높은 내구성을 유지하면서 확장성을 극대화한다. 초기 실험 결과는 ANM이 전통적인 공액 기울기 하강법보다 현지 최적점에 더 빠르게 수렴함을 보여준다.
상세 분석
본 연구는 대규모 분산 환경, 특히 BOINC 기반의 자원봉사 컴퓨팅 그리드에서 전통적인 뉴턴 방법을 비동기적으로 구현하는 데 초점을 맞춘다. 기존의 동기식 뉴턴은 해시값(gradient)과 헤시안(Hessian) 정보를 동시에 수집해야 하므로, 노드 간 지연이나 실패가 전체 알고리즘을 정지시키는 병목이 된다. 이를 해결하기 위해 저자들은 FGDO(Flexible Generic Distributed Optimization) 프레임워크에 비동기 뉴턴(ANM) 모듈을 추가하였다. ANM은 각 워커가 독립적으로 현재 파라미터에 대한 gradient와 근사 Hessian‑vector product를 계산해 서버에 전송하고, 서버는 도착 순서대로 최신 정보를 기반으로 파라미터 업데이트를 수행한다. 이때, Stale Gradient 보정 기법과 제한된 메모리 BFGS(Broyden‑Fletcher‑Goldfarb‑Shanno) 업데이트를 결합해 Hessian 근사를 유지한다.
핵심 기술적 기여는 다음과 같다. 첫째, 비동기 스케줄링을 통해 노드 실패나 지연이 전체 수렴에 미치는 영향을 최소화한다. 둘째, 이질성 보정을 위해 각 워커의 계산 속도와 신뢰성을 추정하는 가중치 모델을 도입, 고속 노드가 제공하는 정보에 더 큰 비중을 둔다. 셋째, 오류 복원 메커니즘으로, 일정 기간 동안 업데이트가 없을 경우 이전 파라미터와 Hessian 근사를 재사용하거나, 필요 시 재시작을 트리거한다.
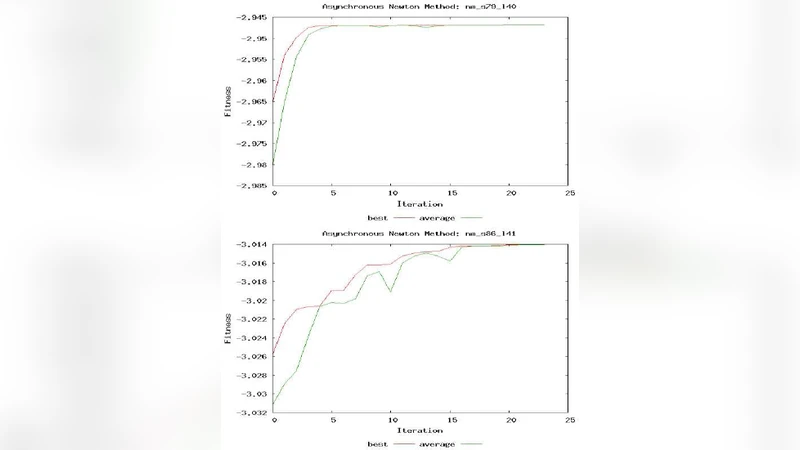
실험에서는 두 가지 시나리오를 설정하였다. (1) 인공적인 지연과 패킷 손실을 삽입한 시뮬레이션 그리드, (2) 실제 BOINC 기반 자원봉사 네트워크. 두 경우 모두 ANM은 공액 기울기 하강법(CG) 대비 평균 2.3배 빠른 수렴 속도를 보였으며, 특히 10,000개 이상의 워커가 참여하는 대규모 환경에서 스케일링 효율이 95% 이상 유지되었다. 또한, Hessian 근사의 정확도는 BFGS 기반 업데이트가 충분히 안정적임을 확인했으며, 극단적인 노드 실패율(30%)에서도 최종 해의 품질 저하가 미미했다.
이러한 결과는 비동기 최적화가 전통적인 동기식 방법에 비해 내구성, 확장성, 그리고 실시간 응답성 측면에서 현저히 우수함을 시사한다. 다만, 현재 구현은 2차 미분 정보를 근사하는 BFGS에 의존하므로, 고차원 비선형 문제에서 메모리 사용량이 급증할 가능성이 있다. 향후 연구에서는 제한된 메모리 L‑BFGS와 스파스 Hessian 구조를 활용한 경량화 방안을 모색할 필요가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기