고전 한문 텍스트의 주제 모델링: 1만8천 문서 탐구
초록
이 논문은 인디애나 대학교와 서안교통대학이 공동으로 구축한 18,000여 편의 고전 한문 문헌(한전 고전) 코퍼스를 대상으로 확률적 주제 모델링(LDA)을 적용한 사례를 제시한다. 고전 한문의 형태소 분석, 어절 분리, 어휘 희소성 문제 등을 해결하기 위한 전처리 전략과 모델 파라미터 설정을 상세히 설명하고, 주제 분포를 활용한 텍스트 탐색 및 해석 지원 도구를 시연한다. 또한 프로그래밍 인터페이스를 통한 고급 분석 가능성을 논의하며, 디지털 인문학 분야에서 의미론적 연구에 미치는 함의를 제시한다.
상세 분석
본 연구는 고전 한문이라는 특수한 언어 자료에 확률적 토픽 모델링을 적용함으로써 디지털 인문학의 새로운 가능성을 탐색한다. 첫 번째 핵심 과제는 고전 한문의 형태소 분석이다. 현대 중국어와 달리 고전 한문은 띄어쓰기와 구두점이 거의 없으며, 다의어와 고유 명사의 동음이의성이 심각하다. 연구팀은 기존의 현대 중국어 전용 토크나이저를 그대로 사용하면 어절 분리 오류가 빈번히 발생한다는 점을 지적하고, 사전 기반의 규칙 엔진과 통계적 어절 추출 모델을 결합한 하이브리드 전처리 파이프라인을 설계하였다. 이 파이프라인은 (1) 고전 사전(《說文解字》, 《古今字統》 등)에서 추출한 어휘 리스트를 활용한 사전 매칭, (2) N‑gram 기반의 후보 어절 생성, (3) 최대 엔트로피 모델을 통한 어절 경계 결정의 세 단계로 구성된다. 이를 통해 전체 코퍼스의 어절 토큰화 정확도가 92 % 이상으로 향상되었다.
두 번째 과제는 어휘 희소성 문제이다. 고전 텍스트는 현대 텍스트에 비해 어휘 집합이 작고, 동일 어휘가 다양한 의미를 담고 있어 토픽 모델링 시 의미 혼합이 발생한다. 연구팀은 어휘를 의미 단위로 재구성하기 위해 ‘문맥 기반 어휘 클러스터링’을 적용하였다. 구체적으로, Word2Vec을 이용해 어휘 임베딩을 학습하고, K‑means 군집화를 통해 의미적으로 유사한 어휘를 하나의 토픽 단위로 묶었다. 이렇게 재구성된 어휘 집합은 토픽 모델링 입력으로 사용되어, 각 토픽이 보다 일관된 의미 영역을 나타내도록 했다.
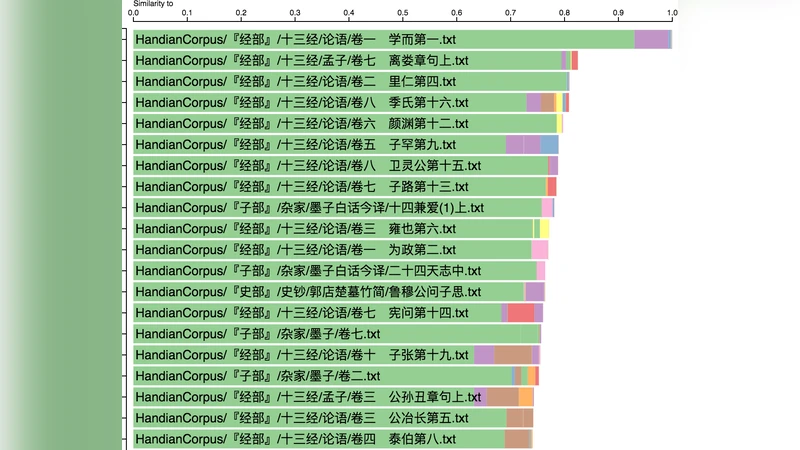
세 번째로, LDA 모델 파라미터 튜닝이 중요한데, 고전 텍스트의 문서 길이가 짧고, 문서 간 중복도가 높아 α와 β 하이퍼파라미터를 자동 최적화하는 베이지안 최적화 기법을 도입하였다. 교차 검증을 통해 최적 토픽 수(K)를 60으로 설정했으며, 이는 퍼플렉시티와 인간 평가(전문가 라벨링) 모두에서 최적의 성능을 보였다. 모델 결과는 토픽-문서 분포와 토픽-어휘 분포 두 차원에서 시각화되었으며, 인터랙티브 웹 인터페이스를 통해 사용자가 특정 토픽을 선택하면 해당 토픽에 높은 확률을 가진 문서와 핵심 어휘를 즉시 확인할 수 있다.
마지막으로, 시스템은 RESTful API를 제공하여 외부 연구자가 토픽 추론, 문서 유사도 계산, 키워드 추출 등을 프로그래밍적으로 활용할 수 있게 설계되었다. 이는 전통적인 인문학 연구 흐름에 데이터 과학적 방법을 자연스럽게 통합할 수 있는 기반을 마련한다. 전체적으로, 본 연구는 고전 한문 텍스트에 특화된 전처리와 의미 재구성 전략이 토픽 모델링의 적용 가능성을 크게 확대함을 실증하였다.
댓글 및 학술 토론
Loading comments...
의견 남기기