배치형 증분 공유 최근접 이웃 밀도 기반 클러스터링 알고리즘
초록
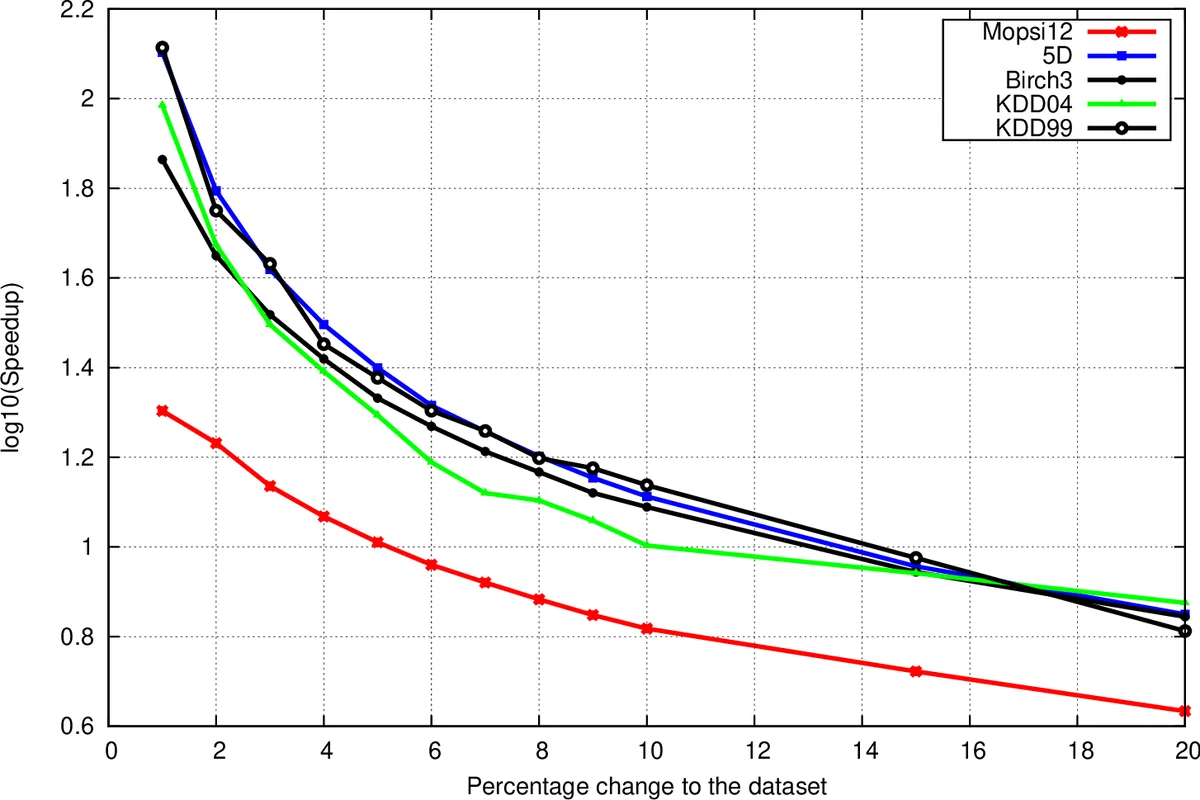
본 논문은 동적 데이터셋에 대한 삽입·삭제 연산을 배치 단위로 처리하면서 기존 SNND와 동일한 클러스터링 결과를 보장하는 BIS‑D 알고리즘을 제안한다. 삽입·삭제 영향을 받는 점들을 효율적으로 구분하고, 확장 KNN 리스트를 활용해 SNN 그래프를 부분적으로만 갱신함으로써 메모리 사용량은 최대 60 % 증가하지만 실행 시간은 SNND 대비 최대 4 order magnitude, InSD 대비 최대 4배까지 가속한다.
상세 분석
BISD는 기존 Incremental Shared Nearest Neighbor Density‑based clustering(InSD)의 두 가지 근본적인 한계를 극복한다. 첫째, InSD는 삭제 연산을 전혀 지원하지 않으며, 둘째, 삽입을 한 번에 하나의 포인트만 처리한다는 점이다. BISD는 입력으로 주어진 변화 집합을 삽입 집합 (n_add)과 삭제 집합 (n_del)으로 분리하고, 먼저 모든 삽입을 일괄 처리한 뒤 삭제를 수행한다. 핵심 아이디어는 각 데이터 포인트에 대해 k개의 최근접 이웃(KNN)뿐 아니라 w(k ≥ k)개의 확장 이웃을 미리 계산해 두는 것이다. 삽입 단계에서는 새 포인트의 w‑리스트를 전체 데이터와 새 포인트 간 거리 계산으로 만든 뒤, 기존 포인트를 세 그룹(T1_add, T2_add, U_add)으로 나눈다. T1_add는 KNN 리스트가 실제로 변하는 포인트, T2_add는 KNN은 변하지 않지만 T1_add에 속한 포인트와 연결된 경우, U_add는 영향을 받지 않는 포인트다. 삭제 단계에서도 동일한 논리를 적용해 T1_del, T2_del, U_del을 정의한다. 이후 T1 = (T1_add ∪ T1_del) − n_del, T2 = ((T2_add ∪ T2_del) − T1) − n_del 로 합쳐진 두 집합을 이용해 SNN 그래프의 인접 리스트를 선택적으로 업데이트한다. 즉, T1에 속한 모든 점은 인접 리스트를 완전 재구성하고, T2에 속한 점은 이웃이 T1에 포함될 때만 갱신한다. 이렇게 하면 전체 그래프를 재구축하는 비용을 크게 절감하면서도, 최종 그래프는 SNND가 처음부터 전체 데이터를 사용해 만든 그래프와 동일하게 된다. 클러스터링 단계는 기존 SNND와 동일하게 핵심점(core), 비핵심점(non‑core), 외부점(outlier)을 구분하고, 핵심점 간 연결을 통해 클러스터를 형성한다. BISD는 전체 SNN 그래프와 확장 KNN 리스트, 클러스터 멤버십을 디스크에 저장해 다음 배치 업데이트 시 재사용한다. 실험에서는 13 k100 k 포인트, 차원 270의 합성·실제 데이터셋을 사용했으며, 메모리 오버헤드는 최대 60 % 수준이지만 실행 시간은 SNND 대비 10³10⁴배, InSD 대비 24배 가량 빠른 것으로 보고된다. 이 결과는 삽입·삭제가 적은 경우 특히 큰 이득을 보이며, 변화 규모가 커질수록 T1·T2에 포함되는 점이 늘어나 속도 향상이 다소 감소한다는 점도 확인한다. 전반적으로 BISD는 배치 기반 증분 클러스터링이라는 새로운 패러다임을 제시하며, 메모리와 시간 복잡도 사이의 실용적인 균형을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기