데이터웨어하우스 인덱스와 물리화뷰 선택 전략
초록
본 논문은 데이터웨어하우스 성능 최적화를 위해 인덱스와 물리화뷰(물리화된 뷰) 선택 방법을 체계적으로 정리하고, 최신 연구 동향을 조망한다. 특히 저자들이 제안한 데이터 마이닝 기반 휴리스틱을 활용해 후보 객체를 효과적으로 축소하고, 선택 문제의 복잡성을 낮추는 기법을 상세히 소개한다.
상세 분석
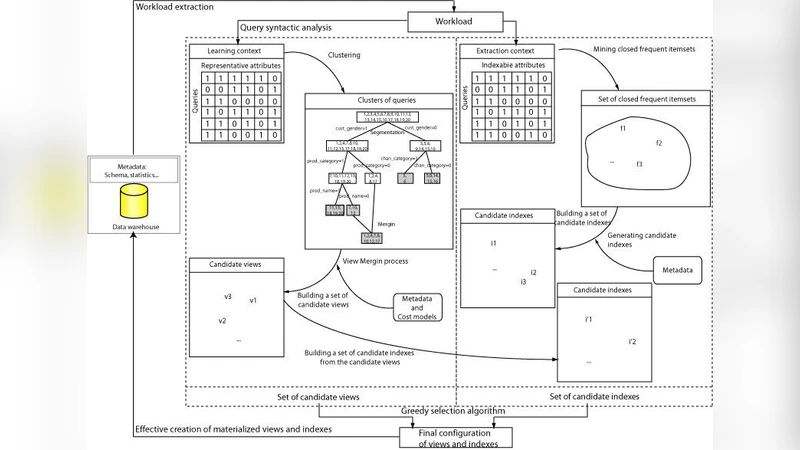
데이터웨어하우스는 대규모 사실 테이블과 다차원 차원을 결합한 스키마를 갖기 때문에, 쿼리 응답 시간 단축을 위해 인덱스와 물리화뷰를 적절히 배치하는 것이 핵심이다. 논문은 기존 연구를 크게 네 가지 패밀리로 구분한다. 첫째, 비용 기반 최적화 기법은 쿼리 워크로드와 시스템 통계치를 이용해 후보 객체의 비용-편익을 정량화한다. 둘째, 규칙 기반 접근은 전문가 지식이나 설계 원칙(예: 자주 사용되는 조인 컬럼에 대한 B‑tree 인덱스, 집계 수준이 높은 뷰에 대한 물리화뷰)으로 후보를 제한한다. 셋째, 진화적·메타휴리스틱 방법은 유전 알고리즘, 입자 군집 최적화 등 탐색 기법을 적용해 전역 최적해에 근접한다. 넷째, 데이터 마이닝 기반 기법은 워크로드 로그에서 빈번한 패턴(예: 자주 등장하는 속성 집합, 공통 집계 함수)을 추출하고, 이 패턴을 기반으로 후보를 자동 생성한다. 저자들은 특히 연관 규칙(Apriori)과 클러스터링을 결합한 하이브리드 모델을 제안한다. 이 모델은 먼저 쿼리 로그를 토큰화하고, 속성 간 동시 등장 빈도를 행렬화한 뒤, 빈도 높은 항목 집합을 추출한다. 이후 추출된 항목 집합을 클러스터링해 유사한 패턴을 그룹화하고, 각 클러스터에 대해 비용‑편익 분석을 수행한다. 이렇게 하면 전체 후보 공간이 수천 개에서 수십 개 수준으로 급감하면서도, 실제 워크로드에 가장 큰 영향을 미치는 인덱스와 물리화뷰를 놓치지 않는다. 또한, 선택된 객체들의 상호 의존성을 고려해 중복 효과를 최소화하고, 저장 공간 제약을 만족하도록 다목적 목표 함수를 최적화한다. 논문은 실험을 통해 기존 비용 기반 및 진화적 방법에 비해 선택 시간 30 % 이상 단축하고, 평균 쿼리 응답 시간 15 % 개선을 달성했음을 보고한다.