조상 인과 추론 효율적 원인‑결과 탐색
본 논문은 관측 및 실험 데이터를 결합하고, 불확실한 독립성 검정 결과를 가중치로 활용하여 조상 관계(간접 인과)를 추정하는 새로운 논리 기반 알고리즘 ACI(Ancestral Causal Inference)를 제안한다. 기존 제약 기반 방법보다 계산량을 크게 줄이면서도 정확도를 유지하고, 예측에 대한 신뢰도 점수를 제공한다. 이론적 정당성(음향성, 점근적 일관성)과 합성·단백질 데이터 실험을 통해 현존 최첨단 방법을 능가함을 입증한다.
저자: Sara Magliacane, Tom Claassen, Joris M. Mooij
본 논문은 제한된 데이터 상황에서 제약 기반 인과 발견이 직면하는 두 가지 주요 문제—통계적 독립성 검정의 경계선 결정 오류와 예측에 대한 신뢰도 부재—를 해결하기 위해 새로운 논리 기반 프레임워크인 Ancestral Causal Inference(ACI)를 제안한다. 기존 연구들은 독립성 진술에 가중치를 부여하고, 이를 기반으로 그래프를 선택하거나 충돌을 해결하는 방식을 사용했지만, 대부분은 탐색 공간이 초지수적으로 커져 계산 비용이 급증하거나, 정확성을 희생하는 휴리스틱을 적용했다.
ACI는 이러한 한계를 극복하기 위해 “조상 관계”(ancestor relation)라는 보다 거친 인과 정보를 핵심 단위로 삼는다. 조상 관계는 변수 X가 Y에 직접 혹은 간접적으로 영향을 미치는지를 나타내는 전이 폐쇄 형태이며, 이는 반사성, 전이성, 반대칭성이라는 세 가지 기본 공리를 만족하는 부분 순서로 정의된다. 조상 구조 자체는 가능한 구조의 수가 ADMG(acyclic directed mixed graph)보다 현저히 적으며, 예를 들어 7개의 변수에 대해 6 × 10⁶개의 조상 구조와 2.3 × 10¹⁵개의 ADMG가 존재한다. 따라서 조상 구조 위에서 최적화 문제를 풀면 탐색 공간이 크게 축소된다.
논문은 먼저 조상 관계와 기존 독립성·비독립성 진술 사이의 논리적 연결 고리를 정리한다. 기존의 Lemma 1은 최소 조건부 독립성/의존성이 특정 변수 Z를 포함할 때 Z가 해당 변수들의 조상 혹은 비조상임을 보인다. 이를 기반으로 ACI는 다섯 개의 새로운 추론 규칙(식 7–11)을 도입한다. 예를 들어, X와 Y가 Z에 대해 독립이고 Z가 X의 조상이 아니면 X는 Y의 조상이 아니다와 같은 규칙이다. 이러한 규칙들은 증명된 음향성을 갖으며, 조상 구조를 제한하는 데 핵심 역할을 한다.
다음으로 ACI는 손실 함수 L(W;I)를 정의한다. 입력 I는 가중된 독립성·비독립성 진술과 조상 관계 진술의 집합이며, 각 진술 i_j는 가중치 w_j를 가진다. 후보 구조 W가 진술 i_j를 만족하지 못하면 w_j가 손실에 더해진다. 최적화 목표는 손실을 최소화하는 조상 구조 W*를 찾는 것이다. 이 문제는 Answer Set Programming(ASP)으로 모델링될 수 있으며, 저자는 최신 ASP 솔버인 clingo 4를 사용해 효율적으로 해결한다.
가중치 부여는 두 가지 방식으로 제시된다. 첫 번째는 빈도주의적 접근으로, p‑값과 사전 지정된 유의 수준 α의 로그 차이를 가중치로 사용한다. 이는 독립성 검정이 약할수록 낮은 가중치를, 강한 종속성 검정이 확실할수록 높은 가중치를 부여한다. 두 번째는 베이지안 접근으로, 데이터 D에 대한 사후 확률 비율을 로그 변환해 가중치로 삼는다. 두 방법 모두 샘플 수 N이 충분히 클 때 점근적 일관성을 보장한다. 특히, α를 N에 따라 감소시키는 방식으로 로그‑p값이 무한대로 발산하도록 함으로써, 큰 표본에서는 진술이 거의 확실히 맞다고 간주한다.
예측에 대한 신뢰도 점수 C(f)는 손실 함수를 이용한 MAP 근사로 정의된다. 특정 특징 f(예: X → Y 조상 관계)를 강제하거나 배제하는 무한 가중치 제약을 추가했을 때 손실 차이가 바로 C(f)이다. 이 점수는 f가 식별 가능한 경우 무한(∞), 반대가 식별 가능한 경우 −∞, 둘 다 식별 불가능한 경우 0이 된다. 따라서 ACI는 단순히 구조를 추정하는 것을 넘어, 각 예측에 대한 신뢰도를 정량화한다.
이론적 분석에서는 제안된 규칙이 음향성을 만족함을 증명하고, 무한 가중치(oracle) 입력에 대해 신뢰도 점수가 정확히 구분되는 정리 1을 제시한다. 또한, 조상 구조 추정이 1차 독립성(조건부 독립성 차수 ≤ 1)만으로도 충분히 식별 가능하다는 ‘order‑1‑complete’ 가설을 제시하지만, 완전성을 보장하려면 고차 규칙이 필요함을 인정한다.
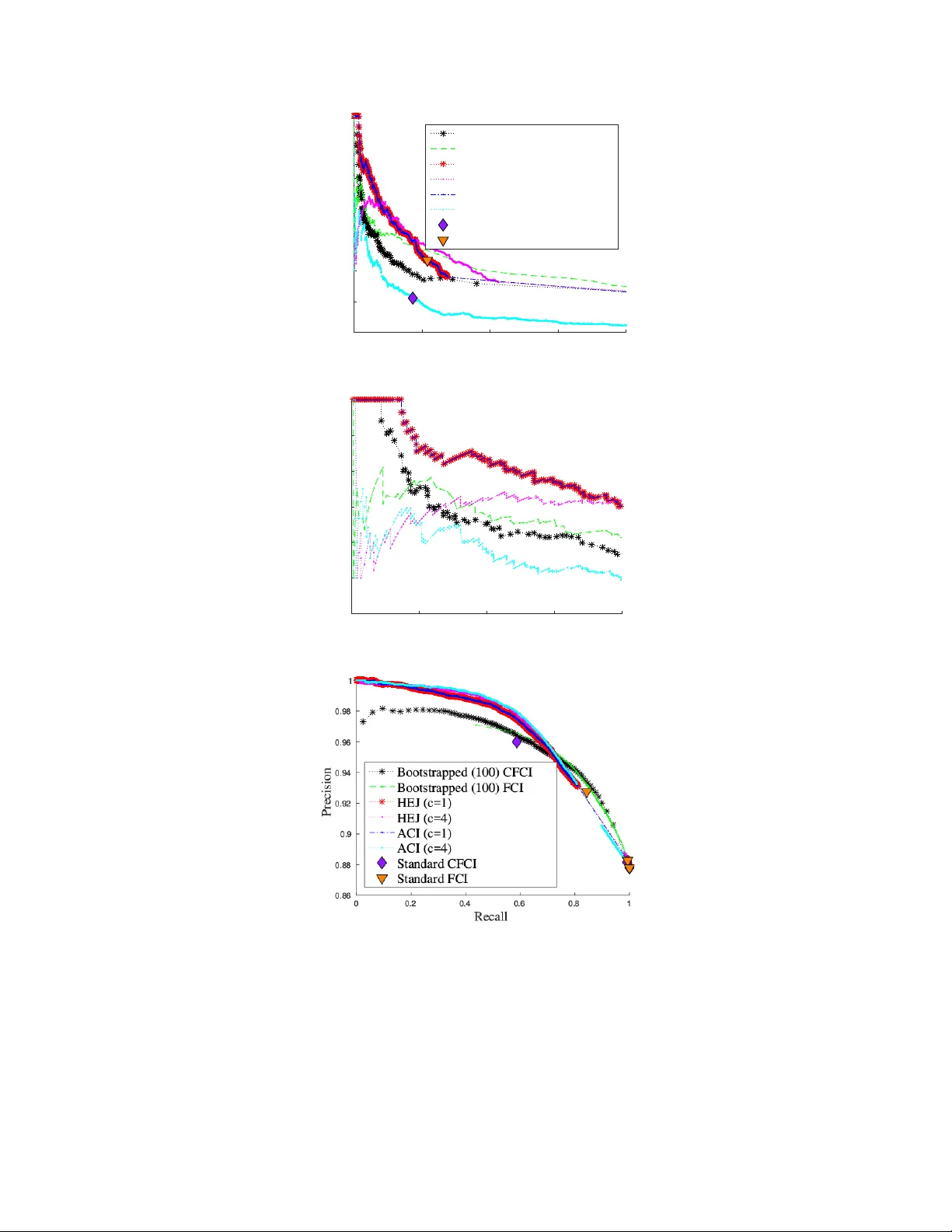
실험 부분에서는 두 가지 데이터셋을 사용한다. 첫 번째는 다양한 그래프와 샘플 크기로 생성된 합성 데이터이며, 여기서 ACI는 기존의 부트스트랩 FCI, CFCI, 그리고 HEJ와 비교해 동일하거나 더 높은 정확도를 보였다. 특히 실행 시간에서는 HEJ 대비 10⁴ ~ 10⁶배, 기존 제약 기반 방법 대비 10² ~ 10³배의 속도 향상을 기록했다. 두 번째는 실제 단백질 상호작용 데이터로, 관측 데이터와 여러 형태의 개입(완전, 부드러운, 메커니즘 변화, 활동 개입)을 결합해 분석했다. ACI는 기존 점수 기반 방법이 놓친 비정상적인 인과 관계를 성공적으로 복원했으며, 조상 관계를 기반으로 한 추정이 실제 생물학적 메커니즘과 잘 부합함을 보였다.
마지막으로 저자들은 ACI의 구현을 오픈소스로 공개했으며, ASP 기반 프레임워크가 새로운 규칙이나 가중치 스키마를 손쉽게 추가할 수 있도록 설계되었다. 이는 연구자들이 다양한 도메인 지식(예: 알려진 직접 인과 관계, 금지된 경로 등)을 손쉽게 통합할 수 있게 한다.
요약하면, ACI는 (1) 조상 관계라는 고수준 인과 표현을 활용해 탐색 공간을 실질적으로 축소, (2) 가중치 기반 손실 함수를 통해 불확실성을 정량화, (3) ASP 기반 최적화로 효율적인 계산을 구현한다는 세 가지 핵심 기여를 제공한다. 이는 제약 기반 인과 발견이 실제 데이터 분석 파이프라인에 보다 실용적으로 적용될 수 있는 길을 열어준다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기