거대한 신경망을 위한 희소게이트 혼합전문가 레이어
초록
**
본 논문은 조건부 연산을 활용해 수천 개의 피드포워드 전문가를 포함하는 희소게이트 Mixture‑of‑Experts(MoE) 레이어를 설계하고, 이를 LSTM 기반 언어 모델과 기계 번역에 적용해 1000배 이상의 파라미터 규모 확대를 실현하면서도 GPU 연산 효율을 크게 손상시키지 않는 방법을 제시한다.
**
상세 분석
**
이 연구는 기존의 조건부 계산 방식이 GPU의 분기 비용, 배치 축소, 네트워크 대역폭 제한 등 실용적 제약에 부딪히는 문제를 정확히 진단하고, 세 가지 핵심 기술로 이를 극복한다. 첫째, ‘Noisy Top‑K’ 게이팅을 도입해 소프트맥스 출력에 가우시안 잡음을 추가하고, 상위 k 개의 전문가만 선택하도록 함으로써 계산량을 크게 줄이면서도 전문가 간 로드 밸런스를 잡음으로 완화한다. 둘째, 데이터 병렬과 모델 병렬을 혼합한 분산 학습 전략을 사용한다. 표준 레이어와 게이팅 네트워크는 데이터 병렬로 복제하되, 각 전문가 파라미터는 하나만 공유하고 여러 디바이스에 분산시켜 배치 크기를 유지한다. 이렇게 하면 전문가당 배치가 감소하는 ‘배치 축소 문제’를 해결하고, 디바이스 수를 늘릴수록 전문가 수를 선형적으로 확장할 수 있다. 셋째, 전문가 활용 균형을 보장하기 위해 두 종류의 정규화 손실을 도입한다. ‘Importance loss’는 배치 전체에서 각 전문가가 받은 게이트 값의 변동계수를 최소화해 모든 전문가가 일정 수준 이상 사용되도록 하고, ‘Load loss’는 실제 예제 수와 가중치 크기의 불균형을 억제한다. 이러한 손실은 단순히 가중치에 대한 L2 정규화가 아니라, 전문가 선택 확률 분포 자체를 정규화한다는 점에서 혁신적이다.
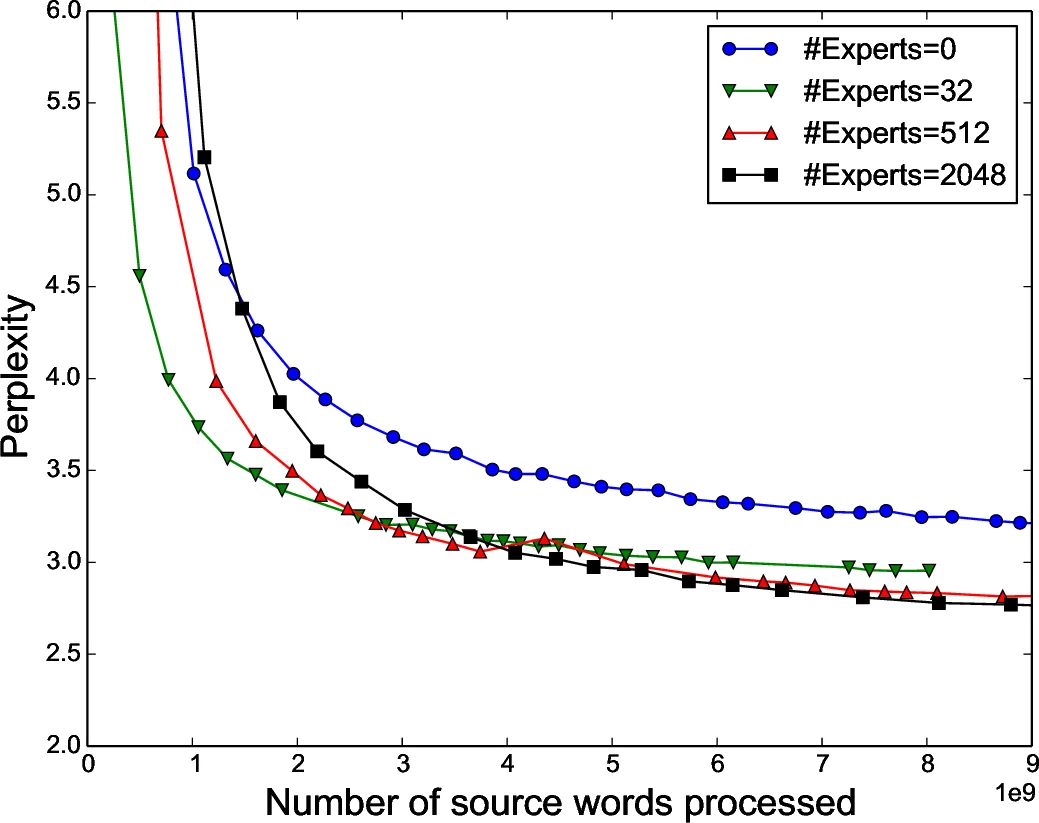
구조적으로는 LSTM 층 사이에 MoE 레이어를 삽입해 시퀀스의 각 타임스텝마다 독립적인 게이팅 결정을 내리게 한다. 이는 ‘컨볼루셔널’ 방식이라 부르며, 동일한 MoE를 여러 타임스텝에 동시에 적용해 배치를 타임스텝 수만큼 확대한다. 실험에서는 1370억 파라미터 규모의 MoE‑LSTM 모델을 구축했으며, 1천억 단어 규모의 언어 모델링 데이터와 WMT 기계 번역 데이터에서 기존 최첨단 모델 대비 퍼플렉서티와 BLEU 점수를 크게 향상시켰다. 특히, 전문가 수를 4배 늘려도 전체 FLOPs 증가율은 1.2배에 불과해 연산 효율이 유지된다.
이 논문은 조건부 연산이 실제 대규모 NLP 시스템에 적용될 수 있음을 증명했으며, 전문가 선택의 희소성, 로드 밸런싱, 그리고 분산 학습 설계라는 세 축을 동시에 만족시키는 설계 패턴을 제시한다. 앞으로 트릴리언 파라미터 규모의 모델을 구축하려는 연구에 있어 핵심적인 설계 원칙이 될 것으로 기대된다.
**
댓글 및 학술 토론
Loading comments...
의견 남기기