깊은 메타 강화학습: 빠른 적응을 위한 새로운 패러다임
본 논문은 재귀 신경망(RNN)을 활용해 메타‑강화학습(meta‑RL) 프레임워크를 제안한다. 하나의 기본 RL 알고리즘으로 네트워크를 학습시키면서, 네트워크 내부의 동적 상태가 완전히 별개의 RL 절차를 구현하도록 만든다. 이렇게 학습된 “학습된 RL 알고리즘”은 훈련 도메인의 구조를 활용해 새로운 과제에 빠르게 적응하고, 샘플 효율성을 크게 향상시킨다. 논문은 7개의 실험을 통해 밴딧 문제와 MDP에서의 성능을 검증하고, 신경과학적 함의도 …
저자: Jane X Wang, Zeb Kurth-Nelson, Dhruva Tirumala
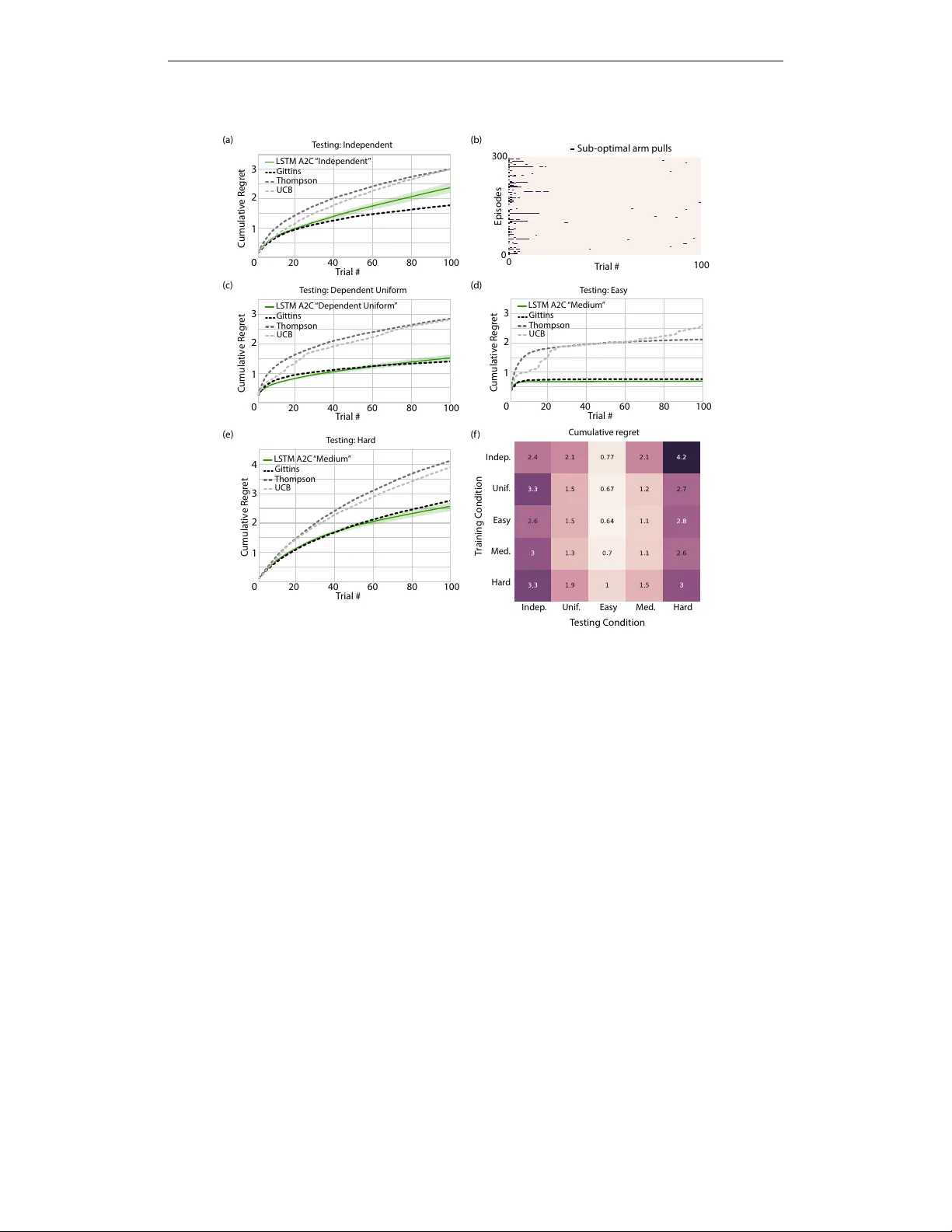
본 논문은 “deep meta‑reinforcement learning”(깊은 메타 강화학습)이라는 새로운 프레임워크를 제안한다. 기존의 딥 강화학습은 하나의 고정된 학습 알고리즘(예: A2C, DQN 등)을 사용해 정책을 직접 최적화한다. 그러나 이러한 접근법은 대량의 데이터와 동일한 작업에 대한 장기적인 훈련을 필요로 하며, 새로운 과제에 빠르게 적응하기 어렵다. 저자들은 이러한 한계를 극복하기 위해, 재귀 신경망(LSTM)을 메타‑학습 메커니즘의 핵심으로 삼는다.
### 1. 메타‑RL의 기본 설계
- **두 단계 학습**: 첫 번째 단계에서는 전통적인 RL 알고리즘(A2C/A3C)을 사용해 LSTM의 가중치를 학습한다. 이때 에이전트는 매 타임스텝마다 이전 행동 a_{t‑1}, 이전 보상 r_{t‑1}, 그리고 (밴딧 실험에서는) 현재 타임스텝 t를 입력받는다.
- **내부 학습 알고리즘**: 파라미터가 고정된 후에도 LSTM의 은닉 상태는 입력된 보상 신호와 행동 히스토리를 바탕으로 자체적인 업데이트 규칙을 수행한다. 즉, 네트워크 자체가 “학습 알고리즘”을 구현한다. 이 내부 알고리즘은 훈련 시에 경험한 과제들의 통계적 구조에 맞춰 최적화된다.
### 2. 형식적 정의
- 사전 분포 D 위에서 MDP 혹은 밴딧 과제 m을 샘플링한다.
- 각 에피소드 시작 시 은닉 상태 h_0을 초기화하고, 에이전트는 히스토리 H_t를 입력받아 정책 π(a_t|H_t)와 가치 v(H_t)를 출력한다.
- 전체 에피소드에 대한 기대 누적 보상 J(θ)=E
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기