분산형 헤시안 프리 최적화로 딥러닝 학습 가속화
초록
본 논문은 딥 뉴럴 네트워크 학습에 헤시안‑프리(Hessian‑Free) 방법을 적용하고, 부정 곡률을 탐지·활용하는 Bi‑CG‑STAB 서브문제 해결기를 도입한 뒤, 데이터 병렬 방식을 이용해 다중 CPU 노드에 분산 구현한다. 실험 결과 MNIST와 TIMIT에서 기존 SGD 대비 수렴 속도가 크게 개선되고, 16~32노드까지 거의 선형적인 스케일업을 달성한다.
상세 분석
이 연구는 딥러닝 최적화에서 흔히 발생하는 ‘고차원·비볼록’ 문제를 두 번째 차수 정보인 헤시안을 활용해 해결하려는 시도이다. 기존 SGD는 사다리꼴 형태의 손실면에서 평탄한 고원(특히 안장점) 근처에서 기울기가 거의 0에 가까워져 학습이 급격히 느려지는 단점을 가지고 있다. 최근 연구(Dauphin et al., 2014)는 안장점을 빠르게 탈피하면 수렴 속도가 크게 향상된다고 보고했으며, 이는 헤시안의 부정 고유값을 이용해 ‘부정 곡률 방향’을 찾아 이동하면 가능함을 시사한다.
Martens(2010)의 헤시안‑프리(HF) 방법은 Hessian‑vector product를 R‑연산자를 통해 효율적으로 계산하고, Gauss‑Newton 근사를 사용해 양의 정부호성을 확보한다. 그러나 이 접근은 부정 곡률을 무시하고, CG(Conjugate Gradient) 내부에서 음의 고유값이 나타날 경우 재시작·감쇠 조정에 의존한다. 논문은 이러한 한계를 극복하기 위해 두 가지 핵심 기법을 제안한다.
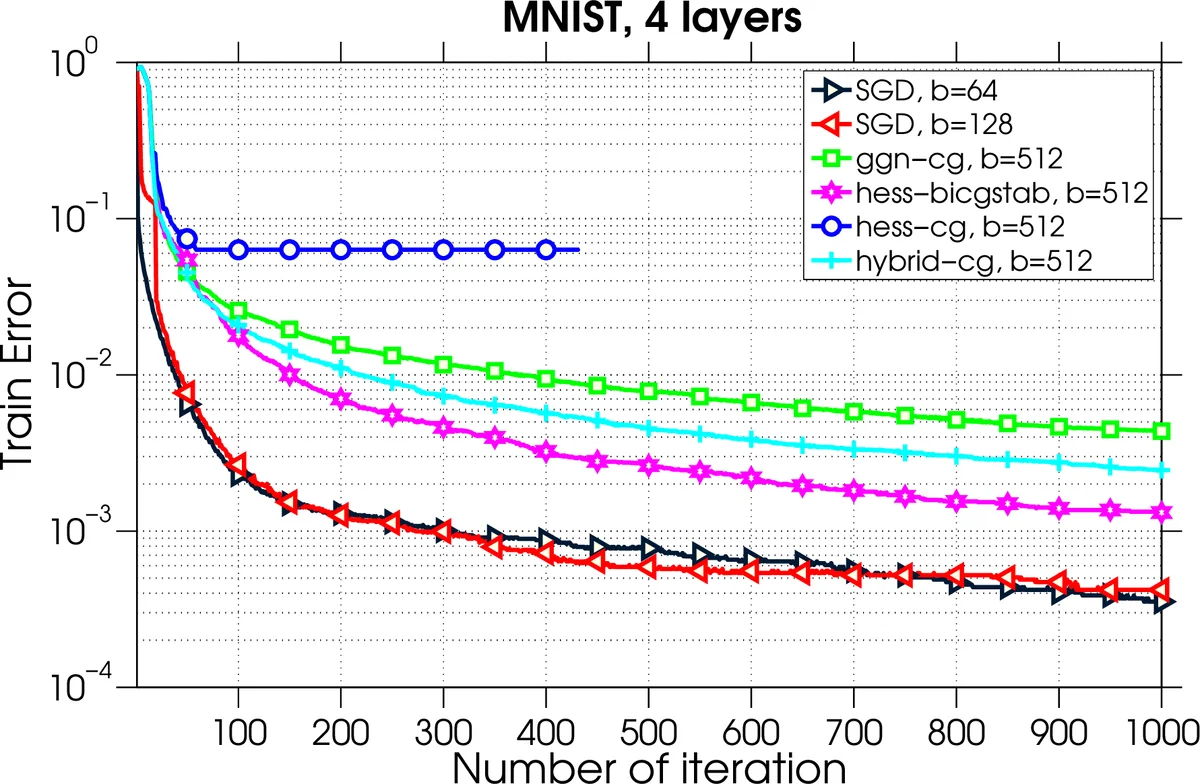
첫째, ‘Stabilized Bi‑Conjugate Gradient (Bi‑CG‑STAB)’를 서브문제 해결기에 적용한다. Bi‑CG‑STAB는 비대칭·불정형 선형 시스템을 해결할 수 있으며, 음의 고유값이 존재해도 수렴이 가능하도록 설계되었다. 이를 통해 실제 스토캐스틱 헤시안(배치 기반 근사) 정보를 그대로 사용하면서도 부정 곡률 방향을 탐지한다. 탐지된 방향 d에 대해 ˜d = −sign(gᵀd)·d 로 변환하면 항상 gᵀ˜d < 0가 보장되어 descent direction이 된다.
둘째, 분산 구현에서는 데이터 병렬(data parallelism)을 채택한다. 각 노드는 전체 파라미터 복사본을 보유하고, 로컬 미니배치에 대해 gradient와 Hessian‑vector product를 계산한다. 이후 MPI Reduce/Allreduce를 통해 전체 gradient와 Hessian‑vector 연산 결과를 집계한다. 이 방식은 모델 병렬에 비해 통신 횟수가 적고, 배치 크기를 크게 늘려도 통신 오버헤드가 제한적이다. 특히 HF는 한 epoch당 몇 번의 CG 반복만 수행하므로 SGD가 매 미니배치마다 동기화해야 하는 비용보다 훨씬 효율적이다.
실험에서는 4‑layer 네트워크(예: MNIST 3‑layer, TIMIT 4‑layer)를 대상으로 배치 크기 5128192, 노드 수 132(총 1152 코어)까지 확장하였다. 결과는 다음과 같다. (1) 목표 함수값 감소 속도가 SGD 대비 2~5배 빠르며, 특히 큰 배치(≥1024)에서 수렴 횟수가 크게 감소한다. (2) 부정 곡률을 활용한 Bi‑CG‑STAB 버전(hess‑bicgstab)은 동일 배치에서도 더 빠른 감소를 보이며, 안장점 근처에서의 진동을 억제한다. (3) 통신 비용 분석에서 HF는 gradient 집계 1회와 CG 반복당 Hessian‑vector 집계 몇 회만 필요해, 노드 수가 늘어날수록 전체 실행 시간이 거의 선형적으로 감소한다.
한계점으로는 (i) Hessian‑vector product 계산이 여전히 두 배의 forward‑backward 연산을 요구해 GPU 환경에서는 메모리·연산 부담이 클 수 있다. (ii) 현재 구현은 CPU 기반 MPI 클러스터에 최적화돼 있어, GPU‑다중노드 환경에서의 성능은 별도 연구가 필요하다. (iii) 부정 곡률 탐지는 Bi‑CG‑STAB의 반복 횟수와 초기 감쇠 파라미터 λ에 민감해, 자동 튜닝 메커니즘이 부재하다.
전반적으로 이 논문은 ‘헤시안‑프리 + 부정 곡률 활용 + 데이터 병렬 분산’이라는 세 축을 결합해, 대규모 딥러닝 학습에서 SGD가 직면한 스케일링·수렴 한계를 효과적으로 완화한다는 점에서 의미가 크다.
댓글 및 학술 토론
Loading comments...
의견 남기기