CNN과 CTC만으로 구현한 엔드투엔드 음성 인식
초록
본 논문은 순환 구조 없이 깊은 합성곱 신경망(CNN)과 연결주의 시간 분류(CTC) 손실을 결합해 TIMIT 음소 인식 과제에서 기존 LSTM 기반 엔드투엔드 시스템과 동등하거나 더 나은 성능을 달성하면서 학습 속도를 크게 향상시킨 방법을 제안한다.
상세 분석
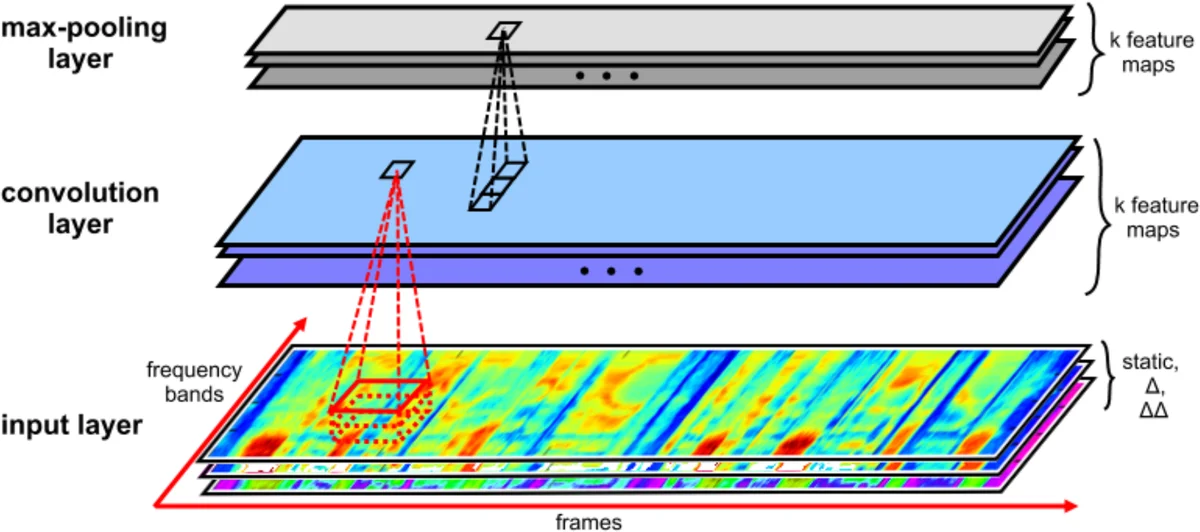
이 연구는 전통적인 HMM‑GMM‑CNN 하이브리드 모델과 최신 RNN‑CTC 엔드투엔드 모델 사이의 장단점을 종합적으로 검토한다. 하이브리드 방식은 각 모듈을 별도로 최적화해야 하는 복잡성을 내포하고, RNN‑CTC는 시간 의존성을 자연스럽게 모델링하지만 계산 비용이 높고 기울기 소실·폭발 문제에 취약하다. 저자들은 이러한 문제를 해결하기 위해 “깊은 2‑D 합성곱” 구조를 채택한다. 입력은 40차원 로그 멜‑필터뱅크에 델타·델타‑델타를 추가한 123차원 특성으로, 시간 축과 주파수 축 모두에 3×5 크기의 작은 필터를 적용해 지역적인 스펙트럼 패턴을 포착한다. 첫 번째 합성곱 층 뒤에만 3×1 크기의 맥스 풀링을 수행해 주파수 차원에서 변동성을 감소시키면서 시간 해상도는 유지한다. 이후 9개의 추가 합성곱 층을 쌓아 receptive field를 확대하고, 각 층마다 128~256개의 채널을 사용해 표현력을 강화한다. 비선형 활성화는 Maxout(2‑piece)으로 선택했는데, 이는 ReLU나 PReLU에 비해 더 풍부한 함수 형태를 제공해 최적화 경로를 완화한다. 마지막에 3개의 1024‑유닛 완전 연결층을 배치하고, 최상위에 CTC 손실을 적용해 정렬되지 않은 라벨 시퀀스를 직접 학습한다. CTC는 블랭크 토큰을 도입해 프레임‑레벨 출력과 목표 라벨 사이의 다중 매핑을 동적 프로그래밍으로 효율적으로 계산한다. 학습은 초기 단계에 Adam(η=1e‑4)으로 빠르게 수렴시키고, 이후 SGD(η=1e‑5)로 미세 조정한다. 드롭아웃(0.3)과 L2 정규화(1e‑5)를 전 층에 적용해 과적합을 방지한다. 실험 결과, 10‑층 CNN‑CTC 모델은 18.2% PER를 기록했으며, 이는 3‑층 Bi‑LSTM(250‑unit) 모델(18.6%) 및 트랜스듀서 기반 모델(18.3%)보다 약간 우수하다. 특히 파라미터 수가 동일한 상황에서 학습 속도가 2.5배 가량 빨라 대규모 데이터셋에 대한 확장 가능성을 시사한다. 추가 실험에서는 층 수 증가, 필터 크기 확대, Maxout 사용이 각각 성능 향상에 기여함을 확인했다. 전체적으로 이 논문은 “깊은 CNN만으로도 충분히 장기 시간 의존성을 학습할 수 있다”는 가설을 실증하고, RNN‑free 엔드투엔드 음성 인식의 실용성을 강조한다.
댓글 및 학술 토론
Loading comments...
의견 남기기