온라인 및 확률적 더글라스 라쳇포드 분할 방법 대규모 머신러닝
본 논문은 전통적인 더글라스‑라쳇포드(DR) 분할 알고리즘을 온라인 및 확률적 환경에 확장한다. 배치 DR은 $O(1/\sqrt{T})$의 regret을, 제안된 온라인 DR은 $O(1)$, 확률적 DR은 $O(1/\sqrt{T})$ 수렴 속도를 보인다. 이론 증명은 간결하고 직관적이며, 실험을 통해 제안 방법의 효율성을 입증한다.
저자: Ziqiang Shi, Rujie Liu
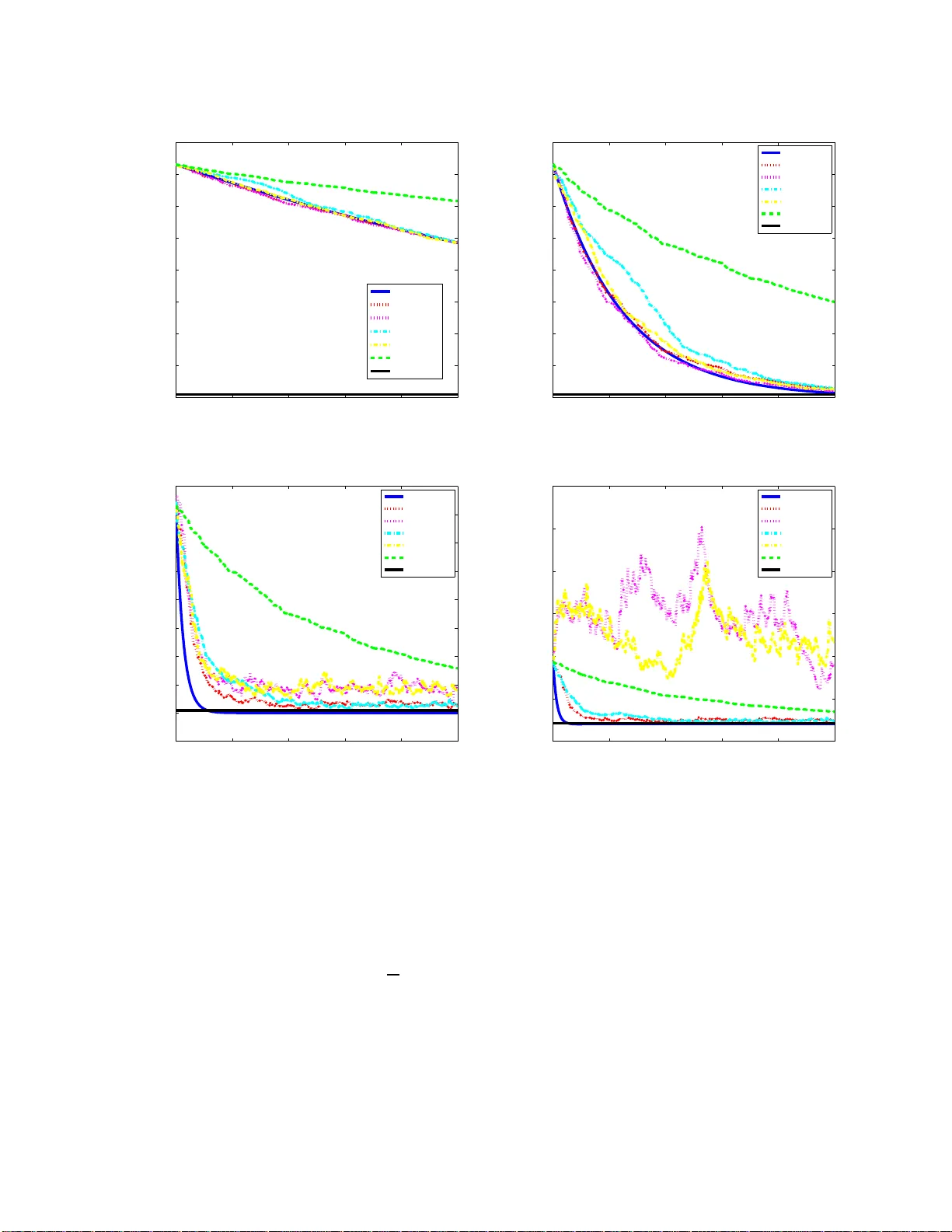
본 논문은 대규모 머신러닝 문제에서 흔히 마주치는 데이터 규모와 순차적 데이터 도착이라는 두 가지 제약을 동시에 해결하고자, 전통적인 더글라스‑라쳇포드(Douglas‑Rachford, DR) 분할 방법을 온라인 및 확률적 형태로 일반화한다. 기존 DR은 두 개의 복합 함수 $g(x)$와 $h(x)$의 합을 최소화하기 위해 다음과 같은 반복식을 사용한다.
1. $x_{t+1}=\operatorname{prox}_{\lambda h}(u_t)$ – 비스무스(비스무스) 정규화 $h$ 의 proximal 연산을 수행한다.
2. $z_{t+1}=\operatorname{prox}_{\lambda g}(2x_{t+1}-u_t)$ – 손실 함수 $g$ 의 proximal 연산을 수행한다.
3. $u_{t+1}=u_t+\lambda(z_{t+1}-x_{t+1})$ – 두 변수 사이의 차를 누적한다.
이때 $g$ 와 $h$ 가 각각 Lipschitz 연속이며 $h$ 가 비스무스라면, 기존 연구에서는 $\|\epsilon_g(x,\lambda)\|^2=O(1/t)$ 라는 정확도 지표를 통해 $f_T(x_T)-f_T(x^\*)=O(1/\sqrt{T})$ 를 보였다. 논문은 이 결과를 재정리하고, $\epsilon_g$ 를 $x-\mathcal R_\lambda^h(x-\lambda\nabla g(x))$ 로 정의해, DR이 실제 최적점에 얼마나 근접하는지를 명시적으로 측정한다.
**온라인 DR(oDR)**
온라인 설정에서는 매 단계마다 새로운 손실 $g_t$ 가 주어지고, 전체 손실의 평균을 최소화하는 것이 목표이다. 저자는 $z_{t+1}$ 를 $g_t$ 로만 구성한 온라인 버전을 제안한다. 이때 $x_{t+1}$ 은 이전 단계의 $u_t$ 로부터 계산되며, $u_{t+1}$ 은 현재 $z_{t+1}$ 와 $x_{t+1}$ 의 차를 반영한다. 핵심 이론은 각 단계에서 얻는 $x_t$ 와 정적 최적해 $x^\*$ 사이의 거리 $\|x_t-x^\*\|$ 가 $\lambda$ 와 $L_{\nabla g_t}$ 로 제한된 상수에 의해 억제된다는 점이다. 이를 바탕으로 전체 regret $R(T,x^\*)=\frac1T\sum_{t=1}^T
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기