대규모 딥 CNN 설계 공간 탐색
초록
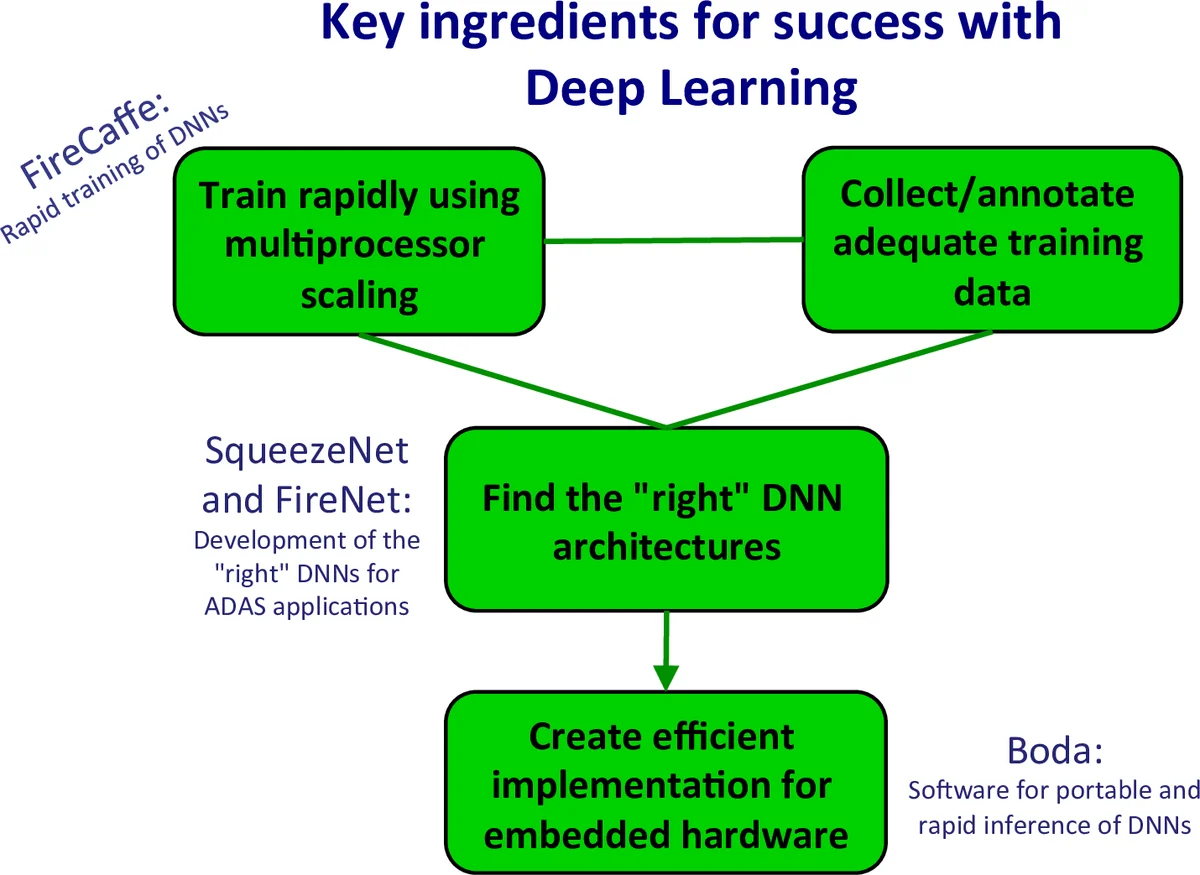
본 논문은 딥 컨볼루션 신경망(CNN)의 방대한 설계 공간을 체계적으로 탐색하기 위한 네 가지 핵심 테마(벤치마크·지표 선정, 빠른 학습, 설계 공간 정의, 설계 공간 탐색)를 제시한다. 특히 대규모 클러스터에서의 효율적 학습 기법과 파라미터 효율성을 극대화한 SqueezeNet을 통해 “올바른” CNN 아키텍처를 찾는 방법론을 실증한다.
상세 분석
이 논문은 딥 CNN 설계가 더 이상 직관에만 의존할 수 없으며, 수십억 개에 달하는 가능한 아키텍처 중 최적을 찾아야 하는 현실적인 문제를 제기한다. 이를 위해 저자는 MESCAL이라는 메타프레임워크를 도입해 네 가지 연구 축을 체계화한다. 첫 번째 축은 실용적인 응용에 맞는 벤치마크와 다중 지표(정확도, 연산량, 메모리, 전력 등)를 선정함으로써 설계 목표를 명확히 정의한다. 두 번째 축은 대규모 GPU/CPU 클러스터에서 데이터 병렬 학습을 가속화하는 기술을 제시한다. 여기서는 파라미터 서버와 리덕션 트리 구조를 비교하고, FireCaffe 시스템을 구축해 ImageNet‑1k 학습 시간을 수시간 수준으로 단축한다. 세 번째 축은 CNN 레이어의 차원(채널 수, 필터 크기, 스트라이드 등)과 전체 네트워크 구조(스킵 연결, 인셉션 모듈 등)를 정량화해 설계 변수들을 명시적으로 모델링한다. 특히 로컬(단일 레이어) 변화와 글로벌(전체 토폴로지) 변화를 구분해 각각이 연산량·파라미터·메모리 요구사항에 미치는 영향을 분석한다. 네 번째 축은 정의된 설계 공간을 실제 탐색하는 방법론으로, 두 단계의 탐색을 수행한다. 마이크로 아키텍처 단계에서는 Fire 모듈과 같은 기본 블록을 조합해 다양한 레이어 구성을 실험하고, 매크로 아키텍처 단계에서는 SqueezeNet과 같은 전체 네트워크 토폴로지를 변형한다. SqueezeNet은 1.2 M 파라미터(≈50 배 압축)에도 불구하고 ImageNet에서 57.5 % Top‑1 정확도를 유지한다는 실험 결과를 보여, 파라미터 효율성의 한계를 재정의한다. 논문 전반에 걸쳐 설계 선택이 연산량, 메모리 대역폭, 에너지 소비와 어떻게 트레이드오프되는지 정량적 모델을 제공한다. 또한, 설계 공간 규모를 30 billion 개 이상의 아키텍처로 추정함으로써, 무작위 탐색이 비현실적임을 강조하고, 자동화된 탐색(예: 강화학습, 베이지안 최적화)과 인간 전문가의 직관을 결합한 하이브리드 접근법의 필요성을 제시한다. 최종적으로 저자는 설계 공간 탐색이 단순히 정확도 향상이 아니라, 실제 배포 환경(모바일, 임베디드, 데이터센터)에서의 제약을 만족시키는 균형 잡힌 설계가 목표임을 강조한다.
댓글 및 학술 토론
Loading comments...
의견 남기기