자원 거의 없이 감성 어휘 사전 만들기
초록
본 논문은 대규모 병렬 코퍼스 없이도 영어 감성 어휘 사전을 다른 언어로 이전하는 방법을 제안한다. 단어 임베딩을 언어 간 선형 변환으로 정렬해 번역 대신 사용하고, 트위터 감성 분류 실험에서 기계 번역과 동등한 성능을 보였다.
상세 분석
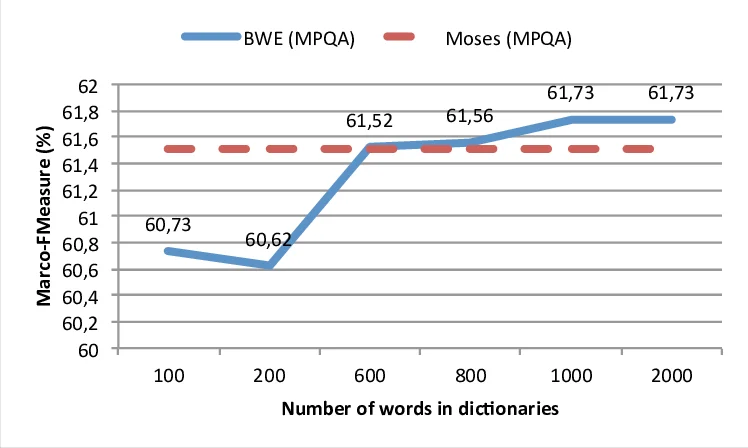
이 연구는 감성 분석에 필수적인 다국어 감성 어휘 사전 구축의 비용 문제를 해결하고자 한다. 기존 방법은 대규모 병렬 텍스트를 필요로 하는 통계적 기계 번역(SMT)이나, 도메인에 특화된 번역 모델을 학습해야 하는 한계가 있었다. 저자들은 이러한 제약을 없애기 위해 두 단계의 접근법을 설계했다. 첫 번째 단계에서는 소스 언어(영어)와 목표 언어(프랑스어, 이탈리아어, 스페인어, 독일어)의 위키피디아 코퍼스를 이용해 각각 200 차원의 word2vec 스킵그램 임베딩을 학습한다. 두 번째 단계에서는 빈도가 높은 50 000개의 단어쌍으로 구성된 작은 양방향 사전을 이용해 선형 변환 행렬 W를 최소제곱법으로 추정한다. 이 변환은 소스 임베딩 x를 목표 임베딩 y에 가깝게 매핑하도록 학습되며, 변환 후 코사인 유사도가 0.65 이상인 목표어들을 후보 번역으로 선택한다. 핵심 가정은 서로 다른 언어의 위키피디아가 동일한 의미공간을 근사한다는 점이며, 이는 Levy와 Goldberg가 제시한 임베딩이 공동 발생 행렬의 선형 분해라는 이론적 근거와 일치한다. 실험에서는 세 가지 감성 클래스(긍정, 부정, 중립)를 구분하는 SVM 분류기에 n‑gram, 대문자, 해시태그, 구두점, 이모티콘 등 전통적인 트위터 특성을 포함하고, 각 감성 사전(MPQA, BingLiu, HGI, NRC)에서 추출된 단어 카운트를 추가 피처로 활용했다. 결과는 사전 없이 진행한 베이스라인(매크로 F1 60.65) 대비, SMT 기반 번역(Moses)과 제안된 임베딩 기반 번역(BWE)이 각각 1~2 포인트 상승했으며, 두 방법을 결합하면 평균 매크로 F1이 61.93까지 도달했다. 특히 BWE는 1 000개의 빈도 높은 단어만으로도 성능 향상을 보였고, 50 000개까지 확장했을 때 최적점을 기록했다. 또한, MPQA 사전의 600개 정도만 수동 번역해 bilingual dictionary에 포함시켜도 SMT 수준을 초과하는 결과를 얻었다. 이는 소량의 인간 번역만으로도 충분히 강력한 다국어 감성 사전을 구축할 수 있음을 시사한다. 한계점으로는 영어와 구조가 유사한 유럽 언어에 주로 적용되었으며, 어순이나 형태가 크게 다른 언어에서는 선형 변환이 충분히 표현력을 제공하지 못할 가능성이 있다. 향후 연구에서는 비선형 매핑, 다중 언어 공동 임베딩, 그리고 도메인 특화 트위터 코퍼스를 활용한 사전 학습 등을 탐색할 계획이다.
댓글 및 학술 토론
Loading comments...
의견 남기기