논리적 접근을 통한 테스트 계획 자동 생성
초록
본 논문은 요구사항 간 논리적 의존성을 부울식으로 모델링하고, 테스트 매니저가 기대하는 테스트 결과를 기반으로 최적의 테스트 실행 순서를 자동으로 생성한다. SAT 솔버를 활용해 테스트 결과의 중복성을 판단하고, 중복을 최소화하는 테스트 플랜을 보장한다.
상세 분석
이 연구는 자동차 산업과 같이 테스트 비용이 높은 도메인에서 “테스트 케이스를 실행하기 전에 결과를 추론해 제외할 수 있는가?”라는 실질적인 문제를 논리적 방법론으로 해결한다. 핵심 아이디어는 세 가지 논리 모델을 결합하는 것이다. 첫째, 요구사항 사양(R)에서 계층 구조와 타입(VF, SF, EC 등)을 이용해 요구사항 간 함의 관계를 부울식으로 변환한다. 둘째, 테스트 스위트(T)는 각 테스트 케이스와 해당 요구사항 집합을 연결하는 동등식(테스트 ⇔ 요구사항들의 AND)으로 표현한다. 셋째, 테스트 플랫폼(P)은 상위·하위 플랫폼 간 요구사항 만족 관계를 함의식(req₀ ⇒ req₁)으로 모델링한다. 이러한 R, T, P를 모두 conjunctive normal form으로 결합하면, 현재까지 실행된 테스트들의 결과 집합을 나타내는 상태 S와 함께 SAT 솔버에 입력해 특정 테스트 케이스가 현재 정보만으로 고정값(true 혹은 false)으로 결정되는지를 판단한다. 즉, R ∧ T ∧ P ∧ S ⊨ test = v (v∈{true,false})이면 해당 테스트는 “중복”이라고 정의한다.
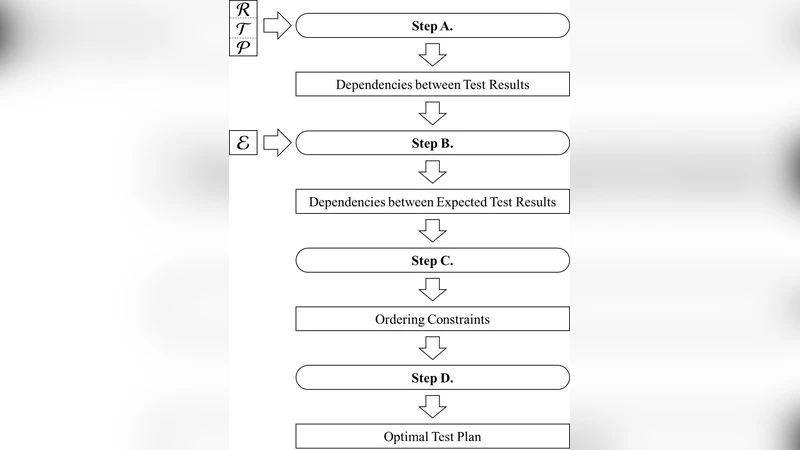
중복 판단이 가능해지면, 논문은 두 단계의 최적화 과정을 제시한다. 단계 A에서는 R, T, P만을 사용해 테스트 결과 간 모든 함의(예: test₀ ⇒ test₁)를 추출한다. 단계 B에서는 매니저가 사전에 기대하는 결과(E)를 부울 변수 xpctd_i 로 표현하고, 이를 R, T, P, 현재 상태 S와 결합해 기대 결과 간 함의를 도출한다(예: ¬xpctd₀ ⇒ ¬xpctd₁). 단계 C에서는 기대 함의와 실제 함의를 교차 검증해 “어떤 테스트 결과가 다른 기대 결과에 의해 중복될 수 있는가”를 판단하고, 그에 따라 “test₀ must precede test₁”와 같은 순서 제약을 생성한다. 마지막 단계 D에서는 이러한 순서 제약을 토폴로지 정렬 등 전형적인 순서 결정 알고리즘에 적용해 최종 테스트 플랜을 만든다.
핵심 기여는 두 가지이다. 첫째, 요구사항·테스트·플랫폼 간 복합적인 논리 관계를 SAT 기반 자동 추론으로 통합함으로써, 인간이 일일이 검토하기 어려운 중복 가능성을 체계적으로 탐지한다. 둘째, 매니저의 기대를 명시적으로 모델링하고, 기대와 실제 논리 구조 사이의 최적 순서를 자동 생성함으로써 “예상 결과가 주어졌을 때 가장 많은 중복을 발견할 수 있는” 테스트 플랜을 보장한다. 논문은 이 알고리즘이 완전함을 정리(존재하는 중복 순서가 있으면 반드시 찾아낸다)으로 증명하고, 실험적으로 자동차 시스템 테스트 사례에 적용해 테스트 실행 시간과 인력 비용을 크게 절감할 수 있음을 보여준다.
이 접근법은 SAT 솔버의 최신 성능에 크게 의존한다는 한계가 있다. 복잡한 대규모 시스템에서는 R·T·P·S의 부울식이 급격히 커져 SAT 해결 시간이 증가할 수 있다. 또한, 매니저의 기대가 부정확하거나 누락될 경우, 최적 플랜이 기대와 다르게 동작할 위험이 있다. 논문은 이러한 경우에도 알고리즘이 정의된 최적성 기준을 유지하지만, 실제 현장 적용 시 기대 입력의 품질 관리가 필요함을 강조한다.
전반적으로, 논리적 의존성 모델링과 SAT 기반 추론을 결합해 테스트 플랜 최적화를 자동화한 점은 테스트 공학 분야에 새로운 패러다임을 제시한다. 특히, 요구사항 트레이스와 테스트 플랫폼 계층을 동시에 고려한다는 점에서 기존의 단순 의존성 분석을 넘어선 통합적 접근이라 할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기