그래프 기반 서지 정보 검색을 위한 자연어 인터페이스
초록
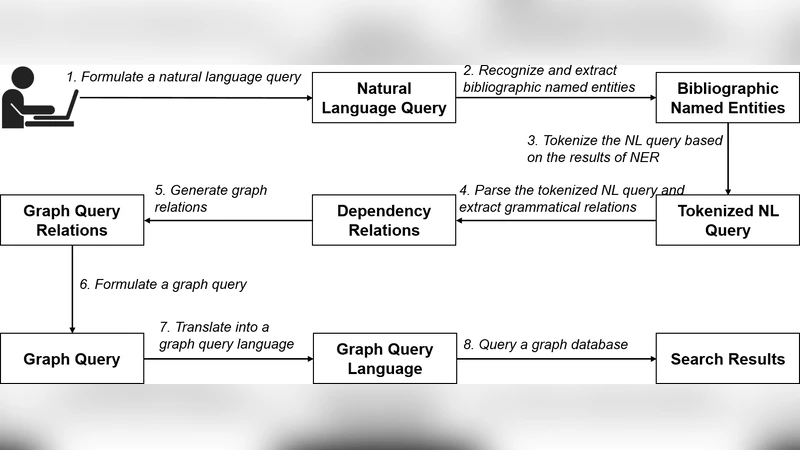
본 논문은 그래프 데이터베이스 위에 구축된 서지 정보 검색 시스템(GIBIR)에 자연어 인터페이스(NLI‑GIBIR)를 추가하는 프레임워크를 제안한다. 사전 기반 명명 엔터티 인식, 토큰화, 의존 구문 분석 등을 순차적으로 적용해 사용자의 명사구 형태 질의를 그래 그래프 쿼리(Cypher 등)로 변환하고, 40개의 테스트 질의 중 39개를 정확히 응답한다는 실험 결과를 제시한다.
상세 분석
이 연구는 기존의 폼 기반·키워드 기반 서지 검색 인터페이스가 복합적인 정보 요구를 표현하기에 한계가 있다는 점을 출발점으로 삼는다. 특히 “저자 John이 작성한 논문”과 같이 명사구 중심의 복합 질의를 자연어로 기술하고자 할 때, 기존 시스템은 태그 선택이나 Boolean 연산을 강제함으로써 사용자의 인지 부하를 증가시킨다. 논문은 이러한 문제를 해결하기 위해 세 가지 핵심 기술을 결합한 프레임워크를 설계한다.
첫째, **사전 기반 명명 엔터티 인식(NER)**이다. 저자, 논문, 학회, 용어, 기관 등 다섯 가지 서지 엔터티 타입을 미리 정의한 사전을 구축하고, Gusfield(1997)의 문자열 매칭 알고리즘을 변형해 삽입·삭제·대체 비용을 1로 설정함으로써 복수·단수 형태를 포괄한다. 이 접근법은 도메인 특화 사전이 충분히 확보된 경우 빠르고 정확한 엔터티 추출을 가능하게 하지만, 동음이의어나 약어 해소와 같은 의미적 소거(disambiguation)를 수행하지 않아 다중 의미가 존재하는 경우 오류가 발생할 수 있다.
둘째, 토큰화와 의존 구문 분석이다. NER 결과를 활용해 다단어 엔터티를 하나의 토큰으로 결합한 뒤, 표준 토크나이저에 입력한다. 이후 의존 구문 분석기를 사용해 “written by”, “published in” 등 관계를 나타내는 동사·전치사 구문을 추출한다. 논문은 의존 구조가 명사구 간 관계를 직접적으로 드러내므로, 복합 구문을 단순히 트리 형태로 변환하는 것보다 그래프 관계 생성에 적합하다고 주장한다. 다만, 구문 분석기는 영어 문법에 최적화된 모델을 사용했으며, 한국어·다국어 질의에 대한 확장성은 검증되지 않았다.
셋째, 그래프 쿼리 변환이다. 추출된 엔터티와 관계를 기반으로 그래프 데이터베이스(Neo4j 등)의 쿼리 언어(Cypher)로 매핑한다. 예를 들어, “papers that were written by John”은 `(a:Author {name:‘John’})-
댓글 및 학술 토론
Loading comments...
의견 남기기